Выведите развертывание вашей LLM (большой языковой модели) на производственный уровень с помощью комплексной настройки автоматического масштабирования и расширенной наблюдаемости метрик vLLM.
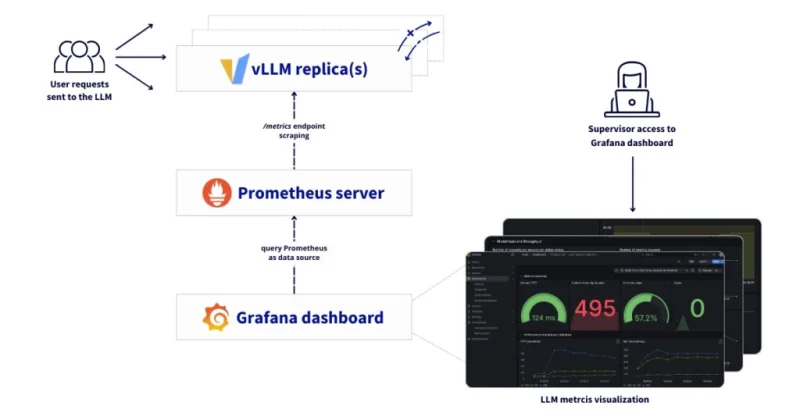
Эта эталонная архитектура описывает комплексное решение для развертывания, автоматического масштабирования и мониторинга рабочих нагрузок LLM на основе vLLM в инфраструктуре OVHcloud. Она сочетает AI Deploy, используемый для обслуживания моделей с автоматическим масштабированием по пользовательским метрикам, и Managed Kubernetes Service (MKS), на котором размещается стек мониторинга и наблюдаемости.
Используя метрики Prometheus уровня приложения, предоставляемые vLLM, AI Deploy может автоматически масштабировать реплики для вывода (inference) на основе реальной нагрузки, обеспечивая высокую доступность, стабильную производительность под нагрузкой и эффективное использование GPU. Этот механизм автомасштабирования позволяет платформе динамически реагировать на всплески трафика, сохраняя предсказуемую задержку для конечных пользователей.
Поверх этого масштабируемого слоя вывода архитектура мониторинга обеспечивает наблюдаемость с помощью Prometheus, Grafana и Alertmanager. Это позволяет осуществлять мониторинг производительности в реальном времени, планирование ресурсов и операционную аналитику, гарантируя при этом полный суверенитет данных для организаций, использующих большие языковые модели (LLM) в производственных средах.
Каковы ключевые преимущества?
- Экономическая эффективность: Используйте управляемые сервисы для минимизации операционных затрат
- Наблюдаемость в реальном времени: Отслеживайте Time-to-First-Token (TTFT), пропускную способность и использование ресурсов
- Суверенная инфраструктура: Все метрики и данные остаются в европейских дата-центрах
- Готовность к production: Постоянное хранилище, высокая доступность и автоматизированный мониторинг
Контекст
AI Deploy
OVHcloud AI Deploy — это платформа Container as a Service (CaaS), созданная для помощи в развертывании, управлении и масштабировании моделей ИИ. Она предоставляет решение, позволяющее оптимально развертывать ваши приложения/API на основе машинного обучения (ML), глубокого обучения (DL) или больших языковых моделей (LLM).
Ключевые моменты, которые следует помнить:
- Простота использования: Используйте свой собственный Docker-образ и разверните его с помощью командной строки или нескольких кликов
- Высокопроизводительные вычисления: Полный спектр доступных GPU (H100, A100, V100S, L40S и L4)
- Масштабируемость и гибкость: Поддерживает автоматическое масштабирование, позволяя вашей модели эффективно обрабатывать меняющиеся нагрузки
- Экономическая эффективность: Оплата за минуту, без дополнительных сборов
Managed Kubernetes Service
OVHcloud MKS — это полностью управляемая платформа Kubernetes, предназначенная для развертывания, эксплуатации и масштабирования контейнерных приложений в production. Она предоставляет безопасную и надежную среду Kubernetes без операционных затрат на управление control plane.
Что следует помнить?
- Экономическая эффективность: Оплачивайте только рабочие узлы и потребляемые ресурсы, без дополнительной платы за control plane Kubernetes
- Полностью управляемый Kubernetes: Сертифицированный upstream Kubernetes с автоматическим управлением control plane, обновлениями и высокой доступностью
- Изначально готов к production: Встроенная интеграция с балансировщиками нагрузки OVHcloud, сетями и постоянным хранилищем
- Масштабируемость и гибкость: Легко масштабируйте рабочие нагрузки и пулы узлов в соответствии с потребностями приложения
- Открытость и переносимость: Основан на стандартных API Kubernetes, что обеспечивает беспрепятственную интеграцию с экосистемами open-source и позволяет избежать привязки к вендору
В следующем руководстве все сервисы развертываются в рамках OVHcloud Public Cloud.
Обзор архитектуры
Эта эталонная архитектура описывает полное, безопасное и масштабируемое решение для:
- Развертывания LLM с помощью vLLM и AI Deploy с использованием автоматического масштабирования на основе пользовательских метрик для обеспечения высокой доступности сервиса — vLLM предоставляет метрики через
/metricsна своем публичном HTTPS-эндпоинте в AI Deploy - Сбора, хранения и визуализации этих метрик vLLM с использованием Prometheus и Grafana на MKS
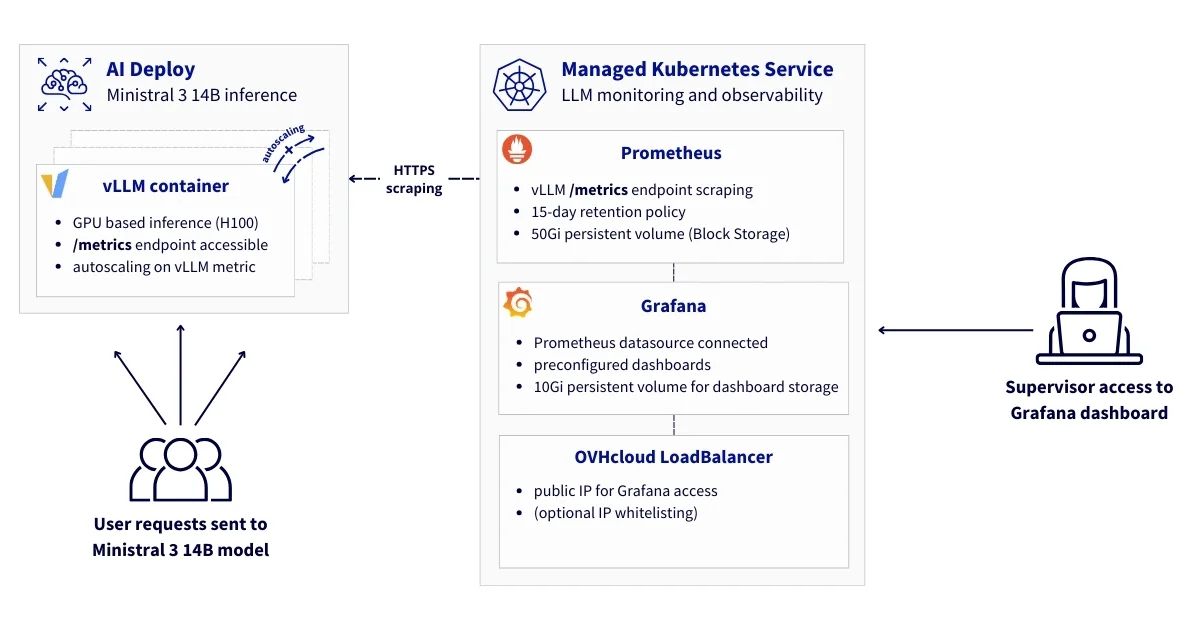
Здесь представлены основные компоненты архитектуры. Решение состоит из трех основных уровней:
- Уровень обслуживания моделей с AI Deploy
- Контейнеры vLLM, работающие на GPU для вывода LLM
- Сервер вывода vLLM, предоставляющий метрики Prometheus
- Автоматическое масштабирование на основе пользовательских метрик для обеспечения высокой доступности
- HTTPS-эндпоинты с аутентификацией по Bearer токену
- Инфраструктура мониторинга и наблюдаемости на базе Kubernetes
- Prometheus для сбора и хранения метрик
- Grafana для визуализации и дашбордов
- Постоянное хранилище (Persistent Volume) для долгосрочного хранения данных
- Сетевой уровень
- Безопасная HTTPS-связь между компонентами
- Балансировщик нагрузки OVHcloud (LoadBalancer) для внешнего доступа
Для дальнейшей работы необходимо проверить некоторые предварительные условия!
Предварительные требования
Прежде чем начать, убедитесь, что у вас есть:
- Учетная запись OVHcloud Public Cloud
- Пользователь OpenStack с ролью
Administrator - Доступный ovhai CLI — установите ovhai CLI
- Доступ к Hugging Face — создайте учетную запись Hugging Face и сгенерируйте токен доступа
- Установленный
kubectlи установленныйhelm(как минимум версия 3.x)
🚀 Теперь у вас есть все ингредиенты для нашего рецепта, пора развернуть Ministral 14B с помощью AI Deploy и Docker-контейнера vLLM!
Руководство по архитектуре: От автомасштабирования к наблюдаемости для LLM, обслуживаемых через vLLM
Давайте настроим и развернем эту архитектуру!
✅ Примечание
В этом примере используется mistralai/Ministral-3-14B-Instruct-2512. Выберите модель с открытым исходным кодом на ваш выбор и следуйте тем же шагам, адаптируя идентификатор модели (из Hugging Face), версии и тип GPU.
Помните, что все следующие шаги можно автоматизировать с помощью API OVHcloud!
Шаг 1 — Управление токенами доступа
Прежде чем развертывать стек мониторинга, эта архитектура начинается с развертывания Ministral 3 14B на OVHcloud AI Deploy, настроенного для автоматического масштабирования на основе пользовательских метрик Prometheus, предоставляемых самим vLLM.
Экспортируйте ваш токен Hugging Face.
export MY_HF_TOKEN=hf_xxxxxxxxxxxxxxxxxxxxСоздайте Bearer-токен, чтобы получить доступ к вашему приложению AI Deploy после его развертывания.
ovhai token create --role operator ai_deploy_token=my_operator_tokenВозвращается следующий вывод:
Id: 47292486-fb98-4a5b-8451-600895597a2b
Created At: 20-01-26 11:53:05
Updated At: 20-01-26 11:53:05
Spec:
Name: ai_deploy_token=my_operator_token
Role: AiTrainingOperator
Label Selector:
Status:
Value: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Version: 1
Теперь вы можете сохранить и экспортировать свой токен доступа:
export MY_OVHAI_ACCESS_TOKEN=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXШаг 2 — Развертывание LLM с использованием AI Deploy
Прежде чем представить стек мониторинга, эта архитектура начинается с развертывания модели Ministral 3 14B на OVHcloud AI Deploy, настроенного на автомасштабирование на основе пользовательских метрик Prometheus, предоставляемых самим vLLM.
1. Определите целевую метрику vLLM для автомасштабирования
Прежде чем приступить к развертыванию конечной точки Ministral 3 14B, необходимо выбрать метрику, которую вы хотите использовать в качестве триггера для масштабирования.
Вместо того чтобы полагаться исключительно на использование ЦП/ОЗУ, AI Deploy позволяет принимать решения об автомасштабировании на основе сигналов уровня приложения.
Для этого вы можете ознакомиться с метриками, предоставляемыми vLLM.
В этом примере вы можете использовать базовую метрику, такую как vllm:num_requests_running, чтобы масштабировать количество реплик на основе реальной нагрузки на вывод (inference).
Это позволяет:
- Быстрее реагировать на всплески трафика
- Лучшее использование GPU
- Снижение задержки вывода при нагрузке
- Эффективное с точки зрения затрат масштабирование
В итоге выбранная конфигурация для масштабирования этого приложения выглядит следующим образом:
| Параметр | Значение | Описание |
|---|---|---|
| Источник метрики | /metrics | Конечная точка Prometheus vLLM |
| Имя метрики | vllm:num_requests_running | Количество выполняемых запросов |
| Агрегация | AVERAGE | Среднее значение по репликам |
| Целевое значение | 50 | Желаемая нагрузка на реплику |
| Мин. реплик | 1 | Базовая производительность |
| Макс. реплик | 3 | Пиковая производительность |
✅ Примечание
Вы можете выбрать метрику, которая лучше всего подходит для вашего случая использования. Вы также можете в любое время применить патч к вашему развертыванию AI Deploy, чтобы изменить целевую метрику для масштабирования.
Когда среднее количество выполняемых запросов превышает 50, AI Deploy автоматически предоставляет дополнительные реплики на GPU.
2. Разверните Ministral 3 14B с использованием AI Deploy
Теперь вы можете развернуть LLM с помощью ovhai CLI.
Ключевые элементы, необходимые для правильного функционирования:
- Вывод на основе GPU:
1 x H100 - Docker-образ vLLM, совместимый с OpenAI:
vllm/vllm-openai:v0.13.0 - Пользовательские правила автомасштабирования на основе метрик Prometheus:
vllm:num_requests_running
Ниже приведена эталонная команда, используемая для развертывания модели mistralai/Ministral-3-14B-Instruct-2512:
ovhai app run
--name vllm-ministral-14B-autoscaling-custom-metric
--default-http-port 8000
--label ai_deploy_token=my_operator_token
--gpu 1
--flavor h100-1-gpu
-e OUTLINES_CACHE_DIR=/tmp/.outlines
-e HF_TOKEN=$MY_HF_TOKEN
-e HF_HOME=/hub
-e HF_DATASETS_TRUST_REMOTE_CODE=1
-e HF_HUB_ENABLE_HF_TRANSFER=0
-v standalone:/hub:rw
-v standalone:/workspace:rw
--liveness-probe-path /health
--liveness-probe-port 8000
--liveness-initial-delay-seconds 300
--probe-path /v1/models
--probe-port 8000
--initial-delay-seconds 300
--auto-min-replicas 1
--auto-max-replicas 3
--auto-custom-api-url "http://<SELF>:8000/metrics"
--auto-custom-metric-format PROMETHEUS
--auto-custom-value-location vllm:num_requests_running
--auto-custom-target-value 50
--auto-custom-metric-aggregation-type AVERAGE
vllm/vllm-openai:v0.13.0
-- bash -c "python3 -m vllm.entrypoints.openai.api_server
--model mistralai/Ministral-3-14B-Instruct-2512
--tokenizer_mode mistral
--load_format mistral
--config_format mistral
--enable-auto-tool-choice
--tool-call-parser mistral
--enable-prefix-caching"Как понять различные параметры этой команды?
a. Запустите ваше приложение AI Deploy
Запустите новое приложение, используя ovhai CLI, и назовите его.
ovhai app run --name vllm-ministral-14B-autoscaling-custom-metric
b. Определите доступ
Определите порт HTTP API и ограничьте доступ вашим токеном.
--default-http-port 8000--label ai_deploy_token=my_operator_token
c. Настройте ресурсы GPU
Укажите тип оборудования (h100-1-gpu), который относится к GPU NVIDIA H100, и их количество (1).
--gpu 1
--flavor h100-1-gpu
⚠️ВНИМАНИЕ! Для этой модели одного H100 достаточно, но если вы хотите развернуть другую модель, вам нужно будет проверить, какой GPU требуется. Обратите внимание, что вы также можете получить доступ к GPU L40S и A100 для развертывания вашей LLM.
d. Настройте переменные окружения
Настройте кэширование для библиотеки Outlines (используется для эффективного генерации текста):
-e OUTLINES_CACHE_DIR=/tmp/.outlines
Передайте токен Hugging Face ($MY_HF_TOKEN) для аутентификации и загрузки модели:
-e HF_TOKEN=$MY_HF_TOKEN
Установите каталог кэша Hugging Face в /hub (где будут храниться модели):
-e HF_HOME=/hub
Разрешите выполнение пользовательского удаленного кода из наборов данных Hugging Face (требуется для некоторого поведения модели):
-e HF_DATASETS_TRUST_REMOTE_CODE=1
Отключите ускорение передачи Hugging Face Hub (для использования стандартной загрузки моделей):
-e HF_HUB_ENABLE_HF_TRANSFER=0
e. Подключите постоянные тома
Подключите два тома постоянного хранилища:
/hub→ Хранит файлы моделей Hugging Face/workspace→ Основной рабочий каталог
Флаг rw означает доступ на чтение и запись.
-v standalone:/hub:rw
-v standalone:/workspace:rw
f. Проверки работоспособности и готовности
Настройте пробы жизнеспособности и готовности:
/healthпроверяет, что контейнер работает/v1/modelsподтверждает, что модель загружена и готова обслуживать запросы
Длительные начальные задержки (300 секунд) можно сократить; они соответствуют времени запуска vLLM и загрузки модели на GPU.
--liveness-probe-path /health
--liveness-probe-port 8000
--liveness-initial-delay-seconds 300
--probe-path /v1/models
--probe-port 8000
--initial-delay-seconds 300
g. Конфигурация автомасштабирования (пользовательские метрики)
Сначала задайте минимальное и максимальное количество реплик.
--auto-min-replicas 1
--auto-max-replicas 3
Это гарантирует базовую доступность (одна реплика всегда работает), позволяя при этом увеличить мощность при пиковой нагрузке.
Затем включите автомасштабирование на основе метрик уровня приложения, предоставляемых vLLM.
--auto-custom-api-url "http://<SELF>:8000/metrics"
--auto-custom-metric-format PROMETHEUS
--auto-custom-value-location vllm:num_requests_running
--auto-custom-target-value 50
--auto-custom-metric-aggregation-type AVERAGE
AI Deploy:
- Собирает метрики с локальной конечной точки
/metrics - Парсит метрики в формате Prometheus
- Извлекает датчик
vllm:num_requests_running - Вычисляет среднее значение по всем репликам
Поведение при масштабировании:
- Когда среднее количество выполняющихся запросов превышает
50, AI Deploy добавляет реплики - При снижении нагрузки количество реплик уменьшается
Такой подход обеспечивает высокую доступность и предсказуемую задержку при изменяющемся трафике.
h. Выбор целевого Docker-образа и команды запуска
Используйте официальный Docker-образ vLLM, совместимый с OpenAI.
vllm/vllm-openai:v0.13.0
Наконец, запустите модель внутри контейнера с помощью Python-команды для запуска API-сервера vLLM:
python3 -m vllm.entrypoints.openai.api_server→ Запускает API-сервер vLLM, совместимый с OpenAI--model mistralai/Ministral-3-14B-Instruct-2512→ Загружает модель Ministral 3 14B из Hugging Face--tokenizer_mode mistral→ Использует токенизатор Mistral--load_format mistral→ Использует формат загрузки моделей от Mistral--config_format mistral→ Обеспечивает соответствие конфигурации модели стандарту Mistral--enable-auto-tool-choice→ Автоматический вызов инструментов при необходимости (function/tool call)--tool-call-parser mistral→ Поддержка вызова инструментов--enable-prefix-caching→ Кэширование префиксов для повышения пропускной способности и снижения задержки
Теперь вы можете запустить эту команду с помощью ovhai CLI.
3. Проверка статуса приложения AI Deploy
Теперь вы можете проверить, работает ли ваше приложение AI Deploy:
ovhai app get <your_vllm_app_id>Ваше приложение в статусе RUNNING? Отлично! В логах можно убедиться, что сервер запущен:
ovhai app logs <your_vllm_app_id>⚠️ВНИМАНИЕ! Этот шаг может занять некоторое время, так как необходимо загрузить LLM-модель.
4. Тестирование работоспособности развертывания
Сначала вы можете отправить промпт в LLM. Выполните следующий запрос, задав свой вопрос:
curl https://<your_vllm_app_id>.app.gra.ai.cloud.ovh.net/v1/chat/completions
-H "Authorization: Bearer $MY_OVHAI_ACCESS_TOKEN"
-H "Content-Type: application/json"
-d '{
"model": "mistralai/Ministral-3-14B-Instruct-2512",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Give me the name of OVHcloud’s founder."}
],
"stream": false
}'Также можно проверить доступ к метрикам vLLM.
curl -H "Authorization: Bearer $MY_OVHAI_ACCESS_TOKEN"
https://<your_vllm_app_id>.app.gra.ai.cloud.ovh.net/metricsЕсли оба теста показывают, что развертывание модели функционирует и вы получаете HTTP-ответы 200, вы готовы перейти к следующему шагу!
Следующий шаг — настройка стека наблюдения и мониторинга. Этот механизм автомасштабирования полностью независим от Prometheus, используемого для наблюдения:
- AI Deploy внутренне опрашивает локальную конечную точку
/metrics - Prometheus собирает метрики с той же конечной точки извне для мониторинга, создания дашбордов и, потенциально, оповещений
Это обеспечивает:
- Единственный источник истины для метрик
- Отсутствие дублирования экспортеров
- Согласованные сигналы для масштабирования и наблюдения
Шаг 3 — Создание кластера MKS
В Панели управления OVHcloud создайте кластер Kubernetes, используя MKS.
Для данного сценария рекомендуется следующая конфигурация:
- Локация: GRA (Гравлин) — можно выбрать тот же регион, что и для AI Deploy
- Сеть: Публичная
- Пул узлов :
- Тип (flavour):
b2-15(или аналогичный) - Количество узлов:
3 - Автомасштабирование:
OFF(выключено)
- Тип (flavour):
- Назовите пул узлов:
monitoring
Вы должны увидеть свой кластер (например, prometheus-vllm-metrics-ai-deploy) в списке вместе со следующей информацией:
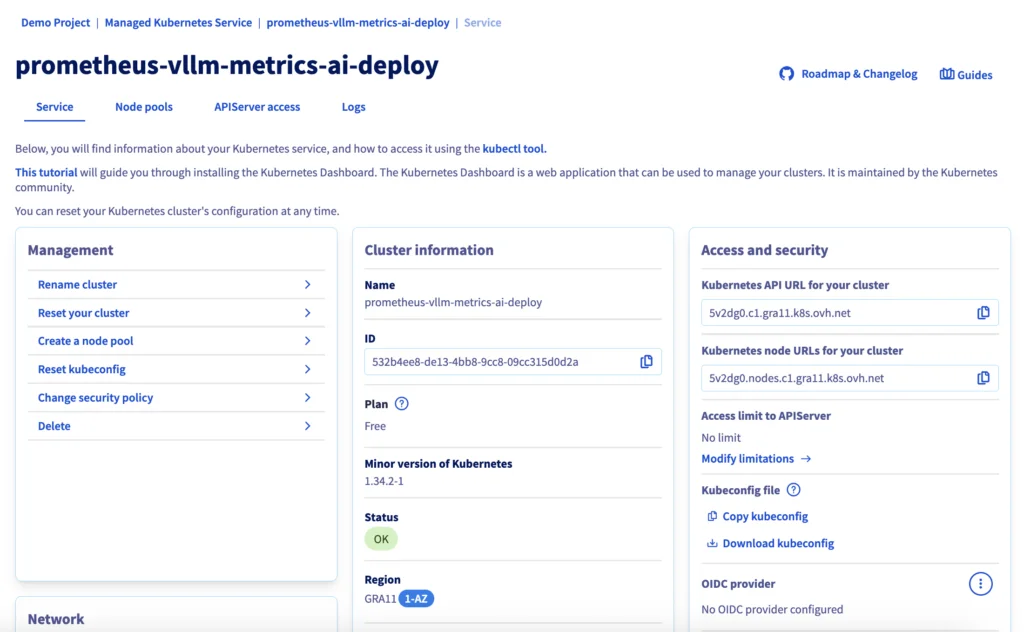
Если статус зелёный с меткой OK, можно переходить к следующему шагу.
Шаг 4 — Настройка доступа к Kubernetes
Скачайте ваш файл kubeconfig из Панели управления OVHcloud и настройте kubectl:
# настройка kubectl для вашего кластера MKS
export KUBECONFIG=/path/to/your/kubeconfig-xxxxxx.yml
# проверка подключения к кластеру
kubectl cluster-info
kubectl get nodesТеперь вы можете создать файл values-prometheus.yaml:
# общая конфигурация
nameOverride: "monitoring"
fullnameOverride: "monitoring"
# конфигурация Prometheus
prometheus:
prometheusSpec:
# срок хранения данных (15d)
retention: 15d
# интервал сбора метрик (15s)
scrapeInterval: 15s
# постоянное хранилище (необходимо для продакшн-развертывания)
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: csi-cinder-high-speed # OVHcloud хранилище
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 50Gi # (можно изменить в соответствии с вашими потребностями)
# сбор метрик vLLM с вашего экземпляра AI Deploy (Ministral 3 14B)
additionalScrapeConfigs:
- job_name: 'vllm-ministral'
scheme: https
metrics_path: '/metrics'
scrape_interval: 15s
scrape_timeout: 10s
# аутентификация с использованием Bearer token AI Deploy, сохраненного в Kubernetes Secret
bearer_token_file: /etc/prometheus/secrets/vllm-auth-token/token
static_configs:
- targets:
- '<APP_ID>.app.gra.ai.cloud.ovh.net' # /! ЗАМЕНИТЕ <APP_ID> на ваш /!
labels:
service: 'vllm'
model: 'ministral'
environment: 'production'
# TLS конфигурация
tls_config:
insecure_skip_verify: false
# kube-prometheus-stack монтирует секрет в /etc/prometheus/secrets/ и делает его доступным для Prometheus
secrets:
- vllm-auth-token
# конфигурация Grafana (уровень визуализации)
grafana:
enabled: true
# отключить автоматическое предоставление источников данных
sidecar:
datasources:
enabled: false
# постоянные дашборды
persistence:
enabled: true
storageClassName: csi-cinder-high-speed
size: 10Gi
# /! ОПРЕДЕЛИТЕ АДМИНИСТРАТИВНЫЙ ПАРОЛЬ - ЗАМЕНИТЕ "test" НА СВОЙ /!
adminPassword: "test"
# доступ через OVHcloud LoadBalancer (публичный IP и управляемый LB)
service:
type: LoadBalancer
port: 80
annotations:
# опционально: ограничить доступ определенным IP-адресам
# service.beta.kubernetes.io/ovh-loadbalancer-allowed-sources: "1.2.3.4/32"
# alertmanager (опционально, но рекомендуется для продакшена)
alertmanager:
enabled: true
alertmanagerSpec:
storage:
volumeClaimTemplate:
spec:
storageClassName: csi-cinder-high-speed
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
# компоненты наблюдаемости кластера
nodeExporter:
enabled: true
kubeStateMetrics:
enabled: true✅ Примечание
В OVHcloud MKS постоянное хранилище обрабатывается автоматически через драйвер Cinder CSI. Когда PersistentVolumeClaim (PVC) ссылается на поддерживаемый
storageClassName, такой какcsi-cinder-high-speed, OVHcloud динамически предоставляет базовый том блочного хранилища и подключает его к узлу, на котором работает под. Это позволяет таким stateful-компонентам, как Prometheus, Alertmanager и Grafana, надежно сохранять данные без какого-либо ручного управления томами, что делает архитектуру полностью cloud-native и операционно простой.
Затем создайте пространство имен monitoring:
# создать пространство имен
kubectl create namespace monitoring
# проверить создание
kubectl get namespaces | grep monitoringНаконец, настройте секрет Bearer token для доступа к метрикам vLLM.
# создать секрет bearer token
kubectl create secret generic vllm-auth-token
--from-literal=token='"$MY_OVHAI_ACCESS_TOKEN"'
-n monitoring
# проверить создание секрета
kubectl get secret vllm-auth-token -n monitoring
# протестировать токен (опционально)
kubectl get secret vllm-auth-token -n monitoring
-o jsonpath='{.data.token}' | base64 -d Хорошо, если всё работает, давайте перейдем к развертыванию.
Шаг 5 — Развертывание стека Prometheus
Добавьте Helm-репозиторий Prometheus и установите стек мониторинга. Развертывание создаст:
- StatefulSet Prometheus с постоянным хранилищем
- Развертывание Grafana с доступом через LoadBalancer
- Alertmanager для будущей настройки оповещений (опционально)
- Вспомогательные компоненты (node exporters, kube-state-metrics)
# добавить Helm-репозиторий
helm repo add prometheus-community
https://prometheus-community.github.io/helm-charts
helm repo update
# установить стек мониторинга
helm install monitoring prometheus-community/kube-prometheus-stack
--namespace monitoring
--values values-prometheus.yaml
--waitЗатем вы можете получить IP-адрес LoadBalancer для доступа к Grafana:
kubectl get svc -n monitoring monitoring-grafanaНаконец, откройте браузер по адресу http://<EXTERNAL-IP> и войдите с:
- Имя пользователя:
admin - Пароль: как настроено в вашем файле
values-prometheus.yaml
Шаг 6 — Создание дашбордов Grafana
На этом шаге вы сможете получить доступ к интерфейсу Grafana, добавить ваш Prometheus в качестве нового источника данных, а затем создать полный дашборд с различными метриками vLLM.
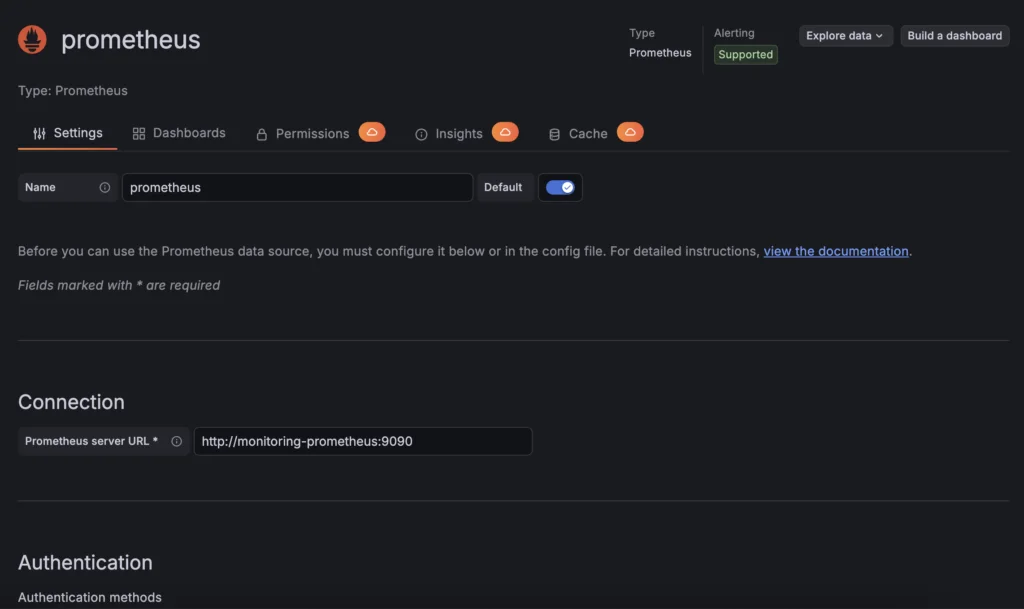
1. Добавьте новый источник данных в Grafana
Прежде всего, создайте новое подключение к Prometheus в Grafana:
- Перейдите в
Connections→Data sources→Add data source - Выберите Prometheus
- Настройте URL:
http://monitoring-prometheus:9090 - Нажмите Save & test
Теперь, когда ваш Prometheus настроен как новый источник данных, вы можете создать свой дашборд Grafana.
2. Создайте ваш дашборд мониторинга
Для начала вы можете использовать следующий предварительно настроенный дашборд Grafana, скачав этот JSON-файл локально:
В меню слева выберите Dashboard:
- Перейдите в
Dashboards→Import - Загрузите предоставленный JSON дашборда
- Выберите Prometheus в качестве источника данных
- Нажмите Import и выберите файл
vLLM-metrics-grafana-monitoring.json
Дашборд обеспечивает мониторинг в реальном времени для Ministral 3 14B, развернутого с контейнером vLLM и OVHcloud AI Deploy.
Теперь вы можете отслеживать:
- Метрики производительности: TTFT, межтокенная задержка, сквозная задержка
- Показатели пропускной способности: Запросов в секунду, скорость генерации токенов
- Использование ресурсов: Использование KV-кэша, активные/ожидающие запросы
- Показатели емкости: Глубина очереди, частота вытеснения
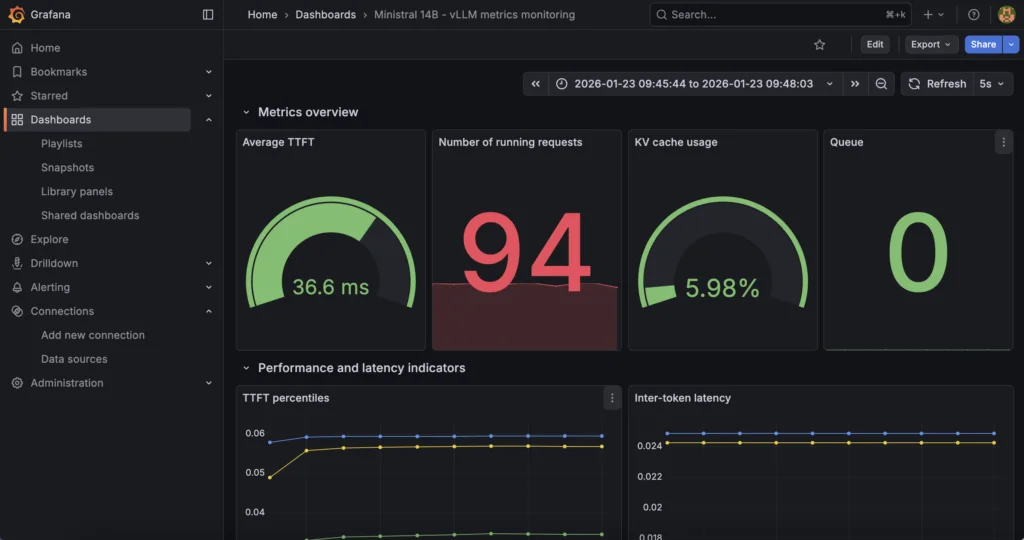
Вот ключевые метрики, отслеживаемые и отображаемые в дашборде Grafana:
| Категория метрики | Метрика Prometheus | Описание | Вариант использования |
|---|---|---|---|
| Задержка | vllm:time_to_first_token_seconds | Время до генерации первого токена | Мониторинг пользовательского опыта |
| Задержка | vllm:inter_token_latency_seconds | Время между токенами | Оптимизация пропускной способности |
| Задержка | vllm:e2e_request_latency_seconds | Общее время выполнения запроса (End-to-End) | Мониторинг SLA |
| Пропускная способность | vllm:request_success_total | Счётчик успешных запросов | Планирование мощности |
| Ресурсы | vllm:kv_cache_usage_perc | Использование памяти KV-кэша | Управление памятью |
| Очередь | vllm:num_requests_running | Активные запросы | Мониторинг нагрузки |
| Очередь | vllm:num_requests_waiting | Запросы в очереди | Обнаружение перегрузки |
| Ёмкость | vllm:num_preemptions_total | Прерывания запросов | Индикатор пиковой нагрузки |
| Токены | vllm:prompt_tokens_total | Обработанные входные токены | Аналитика использования |
| Токены | vllm:generation_tokens_total | Сгенерированные выходные токены | Отслеживание стоимости |
Отлично, теперь в вашем распоряжении:
- Эндпоинт модели Ministral 3 14B, развёрнутый с помощью vLLM благодаря OVHcloud AI Deploy и его стратегиям автомасштабирования на основе пользовательских метрик
- Prometheus для сбора метрик и Grafana для визуализации и дашбордов благодаря OVHcloud MKS
Но как проверить, что всё будет работать при увеличении нагрузки?
Шаг 7 – Тестирование автомасштабирования и визуализация в реальном времени
Первая цель здесь – заставить AI Deploy:
- Увеличить
vllm:num_requests_running - «Насытить» одну реплику
- Запустить масштабирование вверх (scale up)
- Наблюдать увеличение реплик и снижение задержки
1. Стратегия тестирования автомасштабирования
Цель – объединить:
- Высокую конкурентность
- Длинные промпты (с большой нагрузкой на KV-кэш)
- Длинные генерации
- Резкую (burst) нагрузку
Именно на это фактически реагирует автомасштабирование vLLM.
Для этого код на Python может симулировать ожидаемое поведение:
import time
import threading
import random
from statistics import mean
from openai import OpenAI
from tqdm import tqdm
APP_URL = "https://<APP_ID>.app.gra.ai.cloud.ovh.net/v1" # /! ЗАМЕНИТЕ <APP_ID> на ваш /!
MODEL = "mistralai/Ministral-3-14B-Instruct-2512"
API_KEY = $MY_OVHAI_ACCESS_TOKEN
CONCURRENT_WORKERS = 500 # конкурентность (основной триггер масштабирования)
REQUESTS_PER_WORKER = 25
MAX_TOKENS = 768 # нагрузка на генерацию
# случайные промпты
SHORT_PROMPTS = [
"Объясни теорию относительности.",
"Объясни, что такое трансформерная модель.",
"Что такое автомасштабирование в Kubernetes?"
]
MEDIUM_PROMPTS = [
"Объясни, как работают механизмы внимания в трансформерных моделях, включая self-attention и multi-head attention.",
"Опиши, как vLLM управляет KV-кэшем и почему это влияет на производительность инференса."
]
LONG_PROMPTS = [
"Напиши очень подробное техническое объяснение того, как большие языковые модели выполняют инференс, "
"включая токенизацию, поиск эмбеддингов, трансформерные слои, вычисление внимания, использование KV-кэша, "
"управление памятью GPU и как батчинг влияет на задержку и пропускную способность. Используй примеры.",
]
PROMPT_POOL = (
SHORT_PROMPTS * 2 +
MEDIUM_PROMPTS * 4 +
LONG_PROMPTS * 6 # смещение в сторону длинных промптов
)
# совместимость с openai
client = OpenAI(
base_url=APP_URL,
api_key=API_KEY,
)
# базовые метрики
latencies = []
errors = 0
lock = threading.Lock()
# воркер
def worker(worker_id):
global errors
for _ in range(REQUESTS_PER_WORKER):
prompt = random.choice(PROMPT_POOL)
start = time.time()
try:
client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
max_tokens=MAX_TOKENS,
temperature=0.7,
)
elapsed = time.time() - start
with lock:
latencies.append(elapsed)
except Exception as e:
with lock:
errors += 1
# запуск
threads = []
start_time = time.time()
print("Запуск стресс-теста автомасштабирования...")
print(f"Конкурентность: {CONCURRENT_WORKERS}")
print(f"Всего запросов: {CONCURRENT_WORKERS * REQUESTS_PER_WORKER}")
for i in range(CONCURRENT_WORKERS):
t = threading.Thread(target=worker, args=(i,))
t.start()
threads.append(t)
for t in threads:
t.join()
total_time = time.time() - start_time
# результаты
print("n=== РЕЗУЛЬТАТЫ ТЕСТИРОВАНИЯ АВТОМАСШТАБИРОВАНИЯ ===")
print(f"Всего отправлено запросов: {len(latencies) + errors}")
print(f"Успешных запросов: {len(latencies)}")
print(f"Ошибок: {errors}")
print(f"Общее время выполнения: {total_time:.2f}с")
if latencies:
print(f"Средняя задержка: {mean(latencies):.2f}с")
print(f"Минимальная задержка: {min(latencies):.2f}с")
print(f"Максимальная задержка: {max(latencies):.2f}с")
print(f"Пропускная способность: {len(latencies)/total_time:.2f} зап/с")Как можно убедиться, что автомасштабирование работает и нагрузка обрабатывается корректно без резкого роста задержки?
2. Мониторинг на уровне оборудования и платформы
Во-первых, Grafana от AI Deploy отвечает на вопрос: «Какие ресурсы используются и сколько существует реплик?».
Использование GPU, память GPU, CPU, RAM и количество реплик отслеживаются через Grafana OVHcloud AI Deploy (URL мониторинга), который предоставляет метрики инфраструктуры и среды выполнения для приложения AI Deploy. Этот уровень обеспечивает видимость насыщения ресурсов и событий масштабирования, управляемых самой платформой AI Deploy.
Доступ к нему осуществляется по следующему URL (не забудьте заменить <APP_ID> на ваш): https://monitoring.gra.ai.cloud.ovh.net/d/app/app-monitoring?var-app=<APP_ID>&orgId=1
Например, проверьте метрики GPU/RAM:
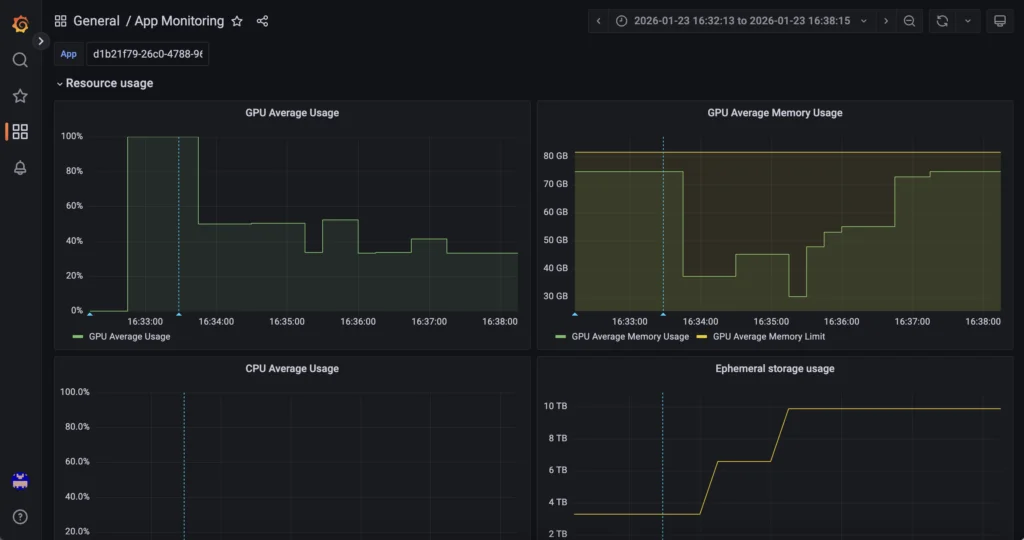
Вы также можете отслеживать масштабирование вверх и вниз в реальном времени, а также информацию о HTTP-вызовах и многое другое!
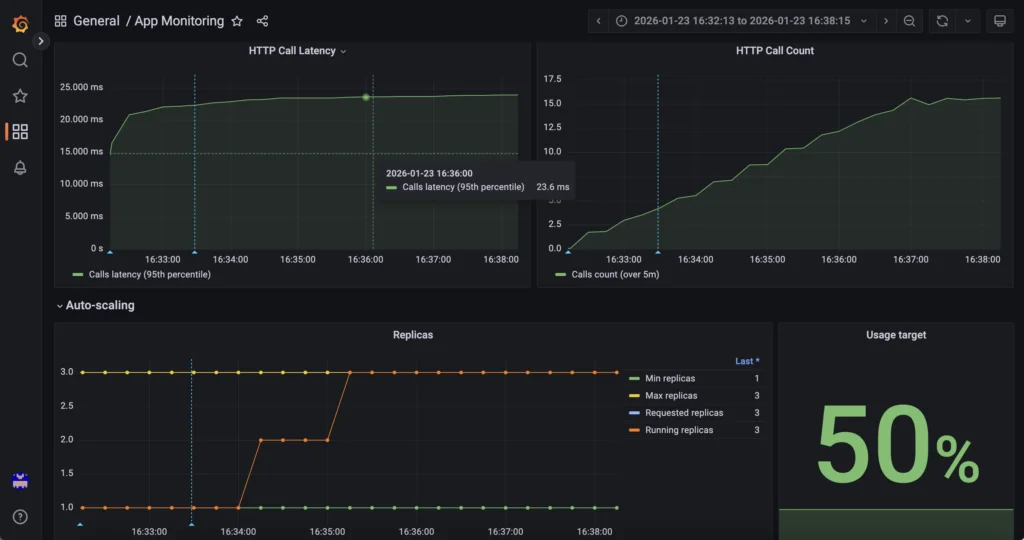
3. Мониторинг на уровне ПО и приложения
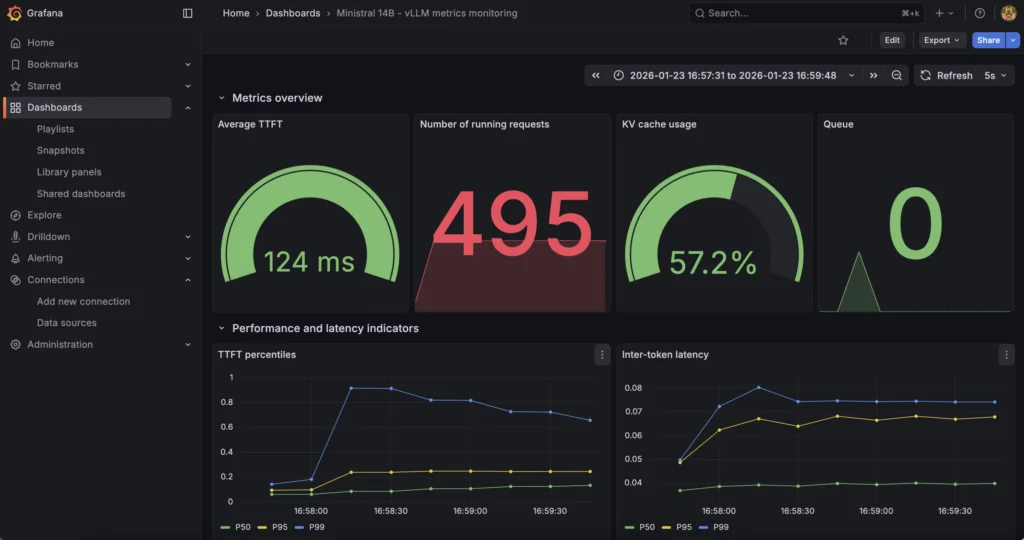
Далее, комбинация MKS + Prometheus + Grafana отвечает на вопрос: «Как ведёт себя движок инференса внутренне».
Фактически, внутренние метрики vLLM (конкурентность запросов, пропускная способность токенов, индикаторы задержки, нагрузка на KV-кэш и т.д.) собираются через эндпоинт vLLM /metrics и собираются Prometheus, работающим на OVHcloud MKS, а затем визуализируются в выделенном экземпляре Grafana. Этот уровень фокусируется на поведении модели и производительности инференса.
Найдите все эти метрики по адресу (просто замените <EXTERNAL-IP>): http://<EXTERNAL-IP>/d/vllm-ministral-monitoring/ministral-14b-vllm-metrics-monitoring?orgId=1
Найдите ключевые метрики, такие как TTF (Time To First Token) и другие:
Вы также можете найти информацию о «Нагрузке на модель и пропускной способности»:
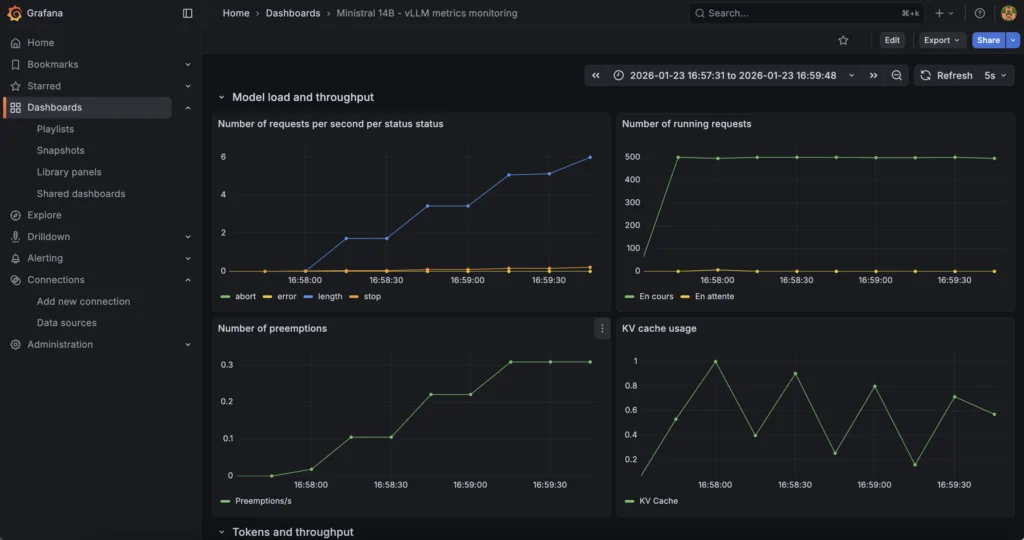
Чтобы пойти дальше и добавить ещё больше метрик, вы можете обратиться к документации vLLM по теме «Prometheus и Grafana».
Заключение
Эта эталонная архитектура предоставляет масштабируемый и готовый к промышленной эксплуатации подход для развёртывания инференса LLM на OVHcloud с использованием AI Deploy и функции автомасштабирования на основе пользовательских метрик.
OVHcloud MKS предназначен для запуска Prometheus и Grafana, обеспечивая безопасный сбор и визуализацию внутренних метрик vLLM, предоставляемых через /metrics эндпоинт.

Комментарии
Категории
Случайное
7 признаков устаревшего сайта: от чего
12 достойных альтернатив Zoho для
Новый год близко: 5 шагов, чтобы
Как разработчику использовать OpenClaw
