Обеспечьте полный цифровой суверенитет своих AI-моделей благодаря сквозному контролю через решения с открытым исходным кодом на Managed Kubernetes Service от OVHcloud.
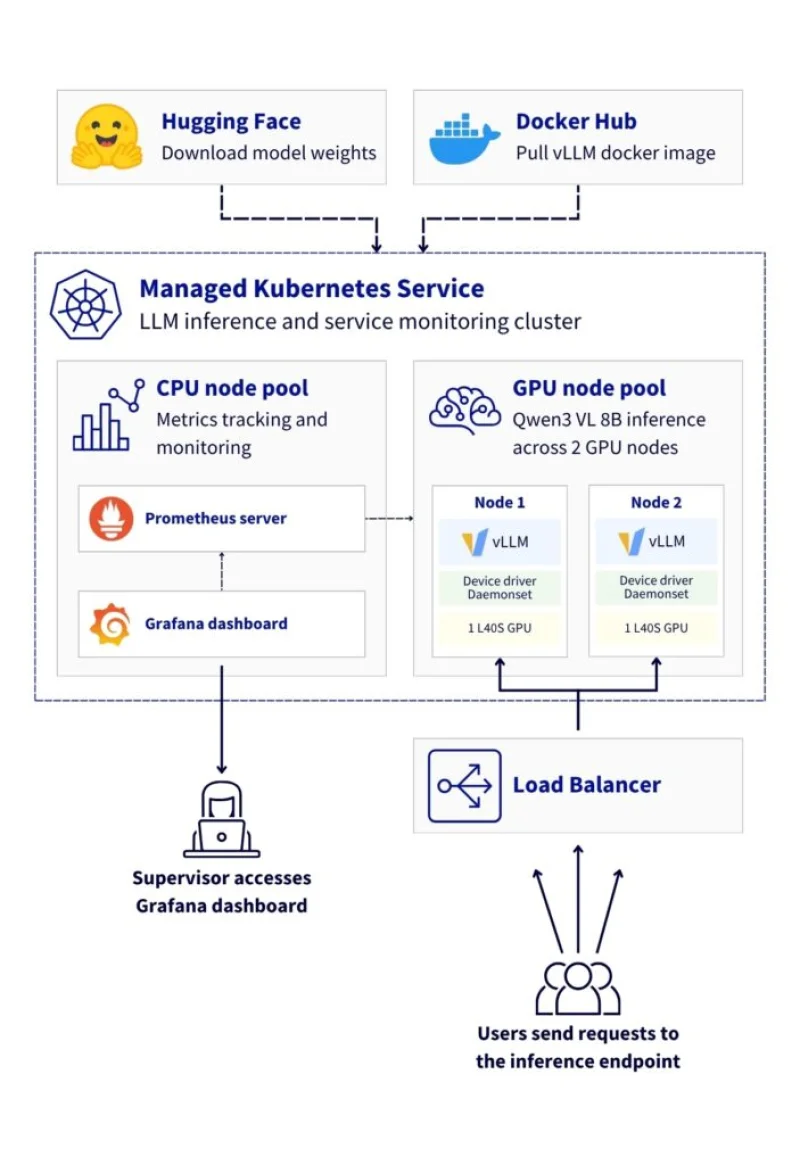
Эта эталонная архитектура демонстрирует, как развернуть систему вывода (inference) для большой языковой модели (LLM) с использованием vLLM на Managed Kubernetes Service (MKS) от OVHcloud. Решение использует GPU NVIDIA L40S для обслуживания мультимодальной модели (визуальная + текстовая) Qwen3-VL-8B-Instruct через API-эндпоинты, совместимые с OpenAI.
Это подробное руководство покажет вам, как развернуть, как автоматически масштабировать и как мониторить рабочие нагрузки LLM на основе vLLM в инфраструктуре OVHcloud.
Каковы ключевые преимущества?
- Экономическая эффективность: Используйте управляемые сервисы, чтобы свести операционные расходы к минимуму
- Наблюдаемость в реальном времени: Отслеживайте время до первого токена (TTFT), пропускную способность и использование ресурсов
- Суверенная инфраструктура: Храните все метрики и данные в европейских дата-центрах
- Масштабируемость по замыслу: Автоматически масштабируйте реплики GPU для вывода на основе реальной нагрузки
Контекст
Managed Kubernetes Service
OVHcloud MKS — это полностью управляемая платформа Kubernetes, предназначенная для развертывания, эксплуатации и масштабирования контейнеризированных приложений в production-среде. Она предоставляет безопасное и надежное окружение Kubernetes без операционных издержек на управление control plane.
Как это вам выгодно?
- Экономически эффективно: Платите только за рабочие узлы и потребляемые ресурсы, без дополнительной платы за control plane Kubernetes
- Полностью управляемый Kubernetes: Сертифицированный upstream Kubernetes с автоматизированным управлением control plane, предоставляемыми обновлениями и высокой доступностью
- Готово к production по замыслу: Встроенная интеграция с балансировщиками нагрузки OVHcloud, сетями и постоянным хранилищем
- Масштабируемо и гибко: Легко масштабируйте рабочие нагрузки, пулы узлов соответствуют спросу приложения
- Открыто и переносимо: Основано на стандартных API Kubernetes, обеспечивает беспрепятственную интеграцию с экосистемами с открытым исходным кодом и позволяет избежать привязки к вендору
В следующем руководстве все сервисы развертываются в рамках OVHcloud Public Cloud.
Обзор архитектуры
Эта эталонная архитектура демонстрирует базовое развертывание vLLM для вывода vision-language модели на Managed Kubernetes Service от OVHcloud, включающее:
- Высокодоступное развертывание с 2 GPU-узлами (NVIDIA L40S)
- Оптимизированное использование GPU с правильной конфигурацией драйверов
- Масштабируемую инфраструктуру, поддерживающую vision-language модели
- Комплексный мониторинг с использованием Prometheus, Grafana и DCGM
- Полную наблюдаемость как для метрик приложения, так и для аппаратных метрик
Поток данных:
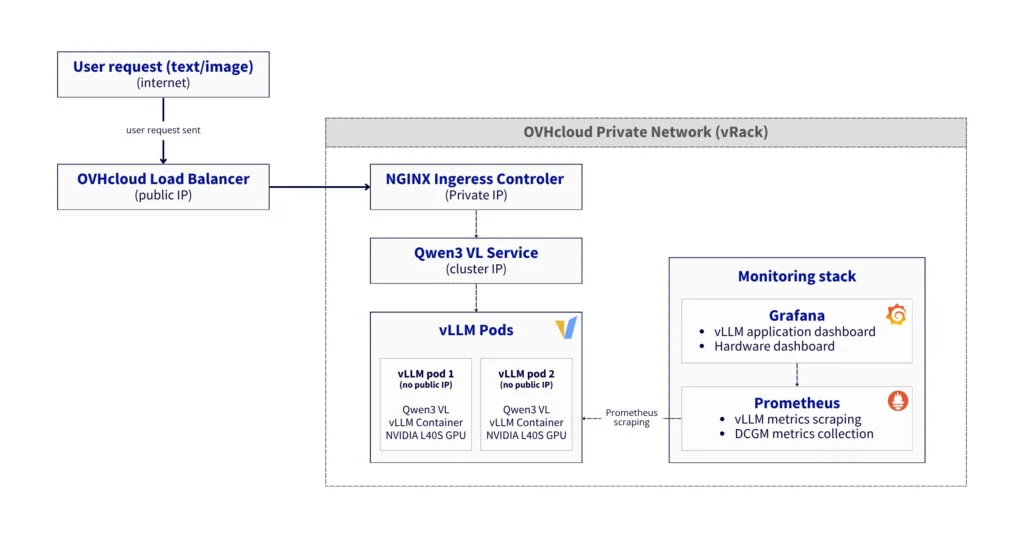
- Запрос на вывод (inference):
- Пользователь → LoadBalancer → Gateway → NGINX Ingress → Сервис «Qwen3 VL» → Pod vLLM → GPU
- Ответ следует обратным путем с поддержкой потоковой передачи
- Сбор метрик:
- Pod'ы vLLM предоставляют эндпоинт
/metrics(порт8000) - DCGM Exporters предоставляют метрики GPU (порт
9400) - Prometheus собирает данные с обоих эндпоинтов каждые 30 секунд
- Grafana запрашивает данные из Prometheus для визуализации
- Pod'ы vLLM предоставляют эндпоинт
- Распределение нагрузки
- NGINX Ingress использует привязку сессии на основе cookie
- Сервис vLLM использует привязку сессии по ClientIP
- Anti-affinity гарантирует размещение 1 пода на GPU-узле
Предварительные требования
Прежде чем начать, убедитесь, что у вас есть:
- Учетная запись OVHcloud Public Cloud
- Пользователь OpenStack с ролью
Administrator - Доступ к Hugging Face – создайте учетную запись Hugging Face и сгенерируйте токен доступа
- Уже установленные
kubectlиhelm(как минимум версии 3.x)
🚀 Теперь, когда у вас есть все ингредиенты, пришло время развернуть рецепт для Qwen/Qwen3-VL-8B-Instruct с использованием vLLM и MKS!
Руководство по архитектуре: Нативное развертывание vLLM на GPU в MKS с полной стековой наблюдаемостью
Эта эталонная архитектура описывает развертывание большой языковой модели с использованием сервера вывода vLLM и Kubernetes, чтобы воспользоваться преимуществами сервиса, который одновременно обладает высокой доступностью и может отслеживаться в реальном времени.
Шаг 1 — Создание кластера MKS и пулов узлов
Из Панели управления OVHcloud создайте кластер Kubernetes, используя MKS.
Перейдите: Public Cloud → Managed Kubernetes Service → Create a cluster (Создать кластер)
1. Настройка кластера
Для текущего случая использования рассмотрите следующую конфигурацию:
- Имя:
vllm-deployment-l40s-qwen3-8b - Локация: 1-AZ Region — Гравлин (
GRA11) - Тарифный план: Бесплатный (или Стандартный)
- Сеть: подключите Приватную сеть (например,
0000 - AI Private Network) - Версия: Последняя стабильная (например,
1.34)
2. Создание пула GPU-узлов
Во время создания кластера настройте пул узлов vLLM для GPU:
- Имя пула узлов:
vllm - Флейвор:
L40S-90 - Количество узлов:
2 - Автомасштабирование: Отключено (OFF)
Почему L40S-90?
- Экономически эффективно для развертывания одной модели (1 GPU на узел)
- Достаточно ОЗУ (90 ГБ) для модели
Qwen3-VL-8B
Вы должны увидеть свой кластер (например, vllm-deployment-l40s-qwen3-8b) в списке, а также следующую информацию:
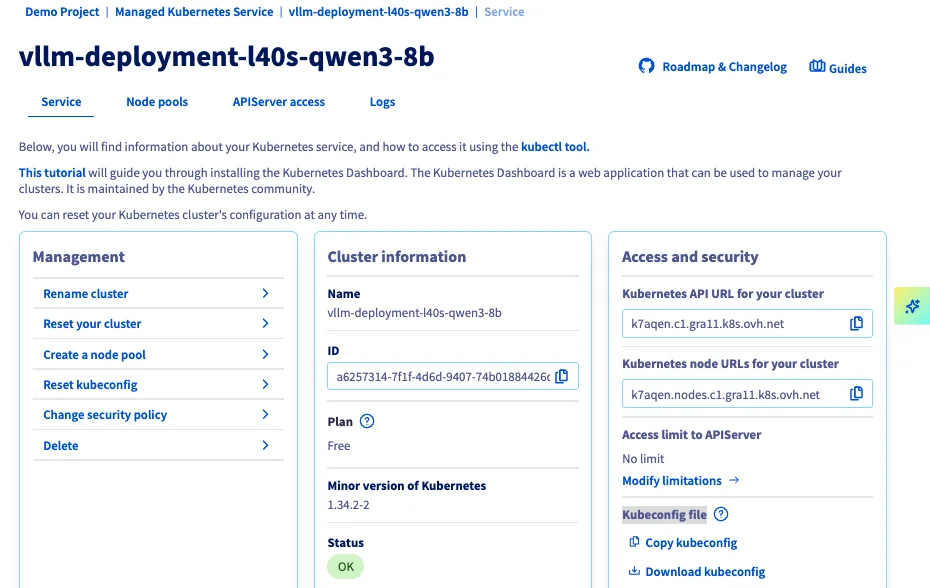
Теперь вы можете настроить пул узлов, выделенный для мониторинга.
3. Создание пула CPU-узлов
В своем кластере нажмите Add a node pool (Добавить пул узлов) и настройте его следующим образом:
- Имя пула узлов:
monitoring - Конфигурация (Flavor):
B2-15 - Количество узлов:
1 - Автомасштабирование: Отключено (OFF)
✅ Примечание
Стек мониторинга может работать на GPU-узлах, если стоимость имеет значение. Выделенный CPU-узел обеспечивает лучшую изоляцию и управление ресурсами.
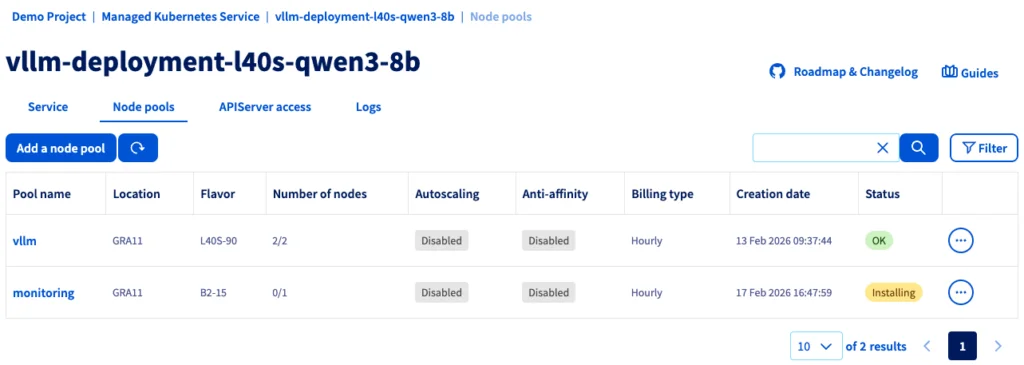
Если статус зеленый с меткой OK, вы можете перейти к следующему шагу.
4. Настройте доступ к Kubernetes
После того как ваши узлы будут подготовлены, вы можете скачать файл Kubeconfig и настроить kubectl для вашего кластера MKS.
# настройте kubectl для вашего кластера MKS
export KUBECONFIG=/path/to/your/kubeconfig-xxxxxx.yml
# проверьте подключение к кластеру
kubectl cluster-info
kubectl get nodesВозвращает:
NAME STATUS ROLES AGE VERSION
monitoring-node-xxxxxx Ready <none> 1d v1.34.2
vllm-node-yyyyyy Ready <none> 1d v1.34.2
vllm-node-zzzzzz Ready <none> 1d v1.34.2
Прежде чем продолжить, добавьте метку к CPU-узлу для рабочих нагрузок мониторинга.
CPU_NODE=$(kubectl get nodes -o json |
jq -r '.items[] | select(.status.allocatable."nvidia.com/gpu" == null) | .metadata.name')
kubectl label node $CPU_NODE node-role=monitoringНаконец, проверьте с помощью следующей команды:
NAME GPU ROLE
monitoring-node-xxxxxx <none> monitoring
vllm-node-yyyyyy 1 <none>
vllm-node-zzzzzz 1 <none>Как только оба узла перейдут в статус Ready, вы можете перейти к следующему шагу.
Шаг 2 — Установите GPU Operator
Для начала рассмотрите возможность настройки GPU Operator.
✅ Примечание
Этот шаг основан на документации OVHcloud: Развертывание GPU-приложения в OVHcloud Managed Kubernetes Service
1. Добавьте репозиторий NVIDIA Helm и создайте пространство имен
Добавьте репозиторий NVIDIA Helm:
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo updateИ создайте пространство имен следующим образом.
kubectl create namespace gpu-operator2. Установите GPU Operator с правильной конфигурацией
GPU Operator должен быть настроен с определенными версиями драйверов, чтобы обеспечить совместимость с контейнерами vLLM.
Однако установка по умолчанию использует свежие драйверы (580.x с CUDA 13.x), которые несовместимы с контейнерами vLLM (CUDA 12.x).
Решение: Принудительно задайте версию драйвера 535.183.01 (CUDA 12.2).
helm install gpu-operator nvidia/gpu-operator
-n gpu-operator
--set driver.enabled=true
--set driver.version="535.183.01"
--set toolkit.enabled=true
--set operator.defaultRuntime=containerd
--set devicePlugin.enabled=true
--set dcgmExporter.enabled=true
--set dcgmExporter.image="dcgm-exporter"
--set dcgmExporter.version="3.1.7-3.1.4-ubuntu20.04"
--set gfd.enabled=true
--set migManager.enabled=false
--set nodeStatusExporter.enabled=true
--set validator.driver.enable=false
--set validator.toolkit.enable=false
--set validator.plugin.enable=false
--timeout 20m✅ Примечание
Указание версии DCGM может потребоваться только в случае проблем с образом по умолчанию (например,
‘ImagePullBackOff’). Если это так, добавьте следующие параметры:--set dcgmExporter.repository="nvcr.io/nvidia/k8s"
--set dcgmExporter.image="dcgm-exporter"
--set dcgmExporter.version="3.1.7-3.1.4-ubuntu20.04"
kubectl get pods -n gpu-operatorОбратите внимание, что все поды должны перейти в состояние Running за 5-10 минут.
Вы также можете проверить доступность GPU:
kubectl get nodes -o json | jq -r '.items[] | select(.status.allocatable."nvidia.com/gpu" != null) | "(.metadata.name): (.status.allocatable."nvidia.com/gpu") GPU(s)"'Возвращает:
vllm-node-yyyyyy: 1 GPU(s)
vllm-node-zzzzzz: 1 GPU(s)
И вы можете протестировать выполнение nvidia-smi:
DRIVER_POD=$(kubectl get pods -n gpu-operator -l app=nvidia-driver-daemonset -o name | head -1)
kubectl exec -n gpu-operator $DRIVER_POD -- nvidia-smiЕсли тесты GPU работают корректно, можно переходить к настройке службы DCGM.
3. Настройте службу DCGM
Зачем требуется DCGM Exporter?
DCGM (Data Centre GPU Manager) — официальный инструмент NVIDIA для мониторинга GPU в производственной среде. Цель — иметь возможность собирать и отображать метрики с обоих GPU-узлов.
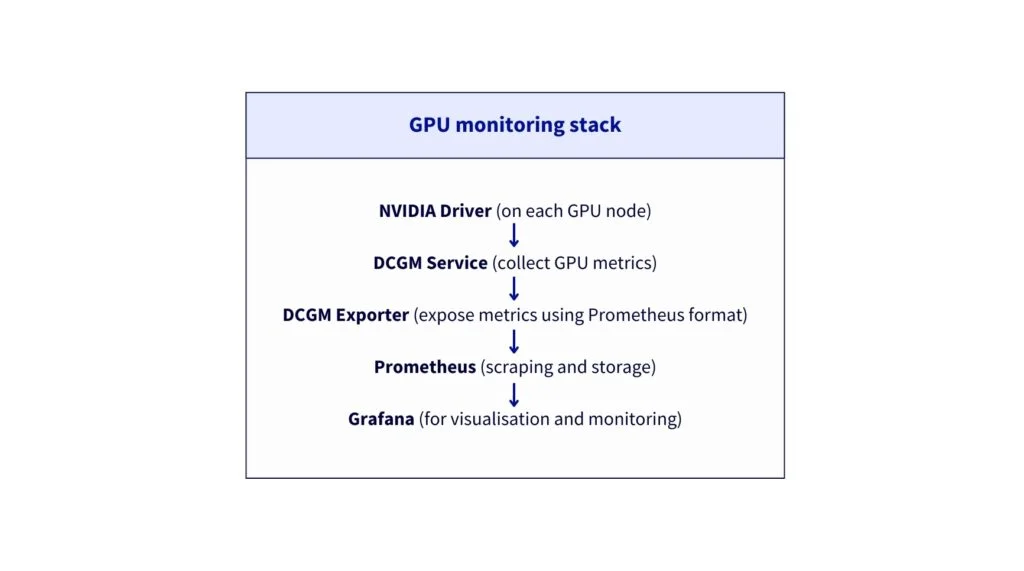
Предоставляемые метрики:
DCGM_FI_DEV_GPU_UTIL— Загрузка GPU (%)DCGM_FI_DEV_GPU_TEMP— Температура GPU (°C)DCGM_FI_DEV_FB_USED— Используемая видеопамять (МБ)DCGM_FI_DEV_FB_FREE— Свободная видеопамять (МБ)DCGM_FI_DEV_POWER_USAGE— Потребляемая мощность (Вт)- И более 50 других метрик GPU
Затем убедитесь, что служба DCGM имеет правильные метки и конфигурацию портов:
kubectl patch svc nvidia-dcgm-exporter -n gpu-operator --type merge -p '{
"metadata": {
"labels": {
"app": "nvidia-dcgm-exporter"
}
},
"spec": {
"ports": [
{
"name": "metrics",
"port": 9400,
"targetPort": 9400,
"protocol": "TCP"
}
]
}
}'Проверьте конечные точки (должны отображаться 2 IP-адреса, по одному на каждый GPU-узел).
kubectl get endpoints nvidia-dcgm-exporter -n gpu-operatorNAME ENDPOINTS AGE
nvidia-dcgm-exporter x.x.x.x:9400,x.x.x.x:9400 17d
Шаг 3 — Разверните Qwen3 VL 8B с сервером вывода vLLM
Развертывание модели Qwen 3 VL 8B на двух узлах с GPU L40S выполняется в несколько этапов.
1. Создайте пространство имен и секрет Hugging Face
Начните с создания пространства имен:
kubectl create namespace vllmЗатем вам необходимо получить свой токен Hugging Face и заменить значение HF_TOKEN на своё:
export HF_TOKEN="hf_xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"Create your secret as follow:
kubectl create secret generic huggingface-secret
--from-literal=token=$HF_TOKEN
--namespace=vllmVerify you obtain the following output by launching:
kubectl get secret huggingface-secret -n vllmNAME TYPE DATA AGE
huggingface-secret Opaque 1 14d
2. Create vLLM deployment configuration
First, you can create vllm-deployment-2nodes.yaml file.
Deploy vLLM:
kubectl apply -f vllm-deployment-2nodes.yamlYou can monitor the deployment (it should take 8-10 minutes for model download and loading).
kubectl get pods -n vllm -o wide -wExpected output after 10 minutes:
NAME READY STATUS RESTARTS AGE IP NODE
qwen3-vl-xxxx-yyy 1/1 Running 0 1d X.X.X.X vllm-node-yyyyyy
qwen3-vl-xxxx-zzz 1/1 Running 0 1d X.X.X.X vllm-node-zzzzzzYou can also check the container logs:
kubectl logs -f -n vllm <pod-name>You should find in the logs: “Uvicorn running on http://0.0.0.0:8000“
Is everything installed correctly? Then let’s move on to the next step.
3. Add service label
Ensure service has the correct label for ServiceMonitor discovery.
kubectl label svc qwen3-vl-service -n vllm app=qwen3-vl --overwriteYou can now verify by launching the following command.
kubectl get svc qwen3-vl-service -n vllm --show-labels | grep "app=qwen3-vl"Returning:
qwen3-vl-service ClusterIP X.X.X.X <none> 8000/TCP 1d app=qwen3-vl
Step 4 – Install NGINX ingress controller
⚠️ Moving beyond Ingress
Follow this tutorial if you want to use Gateway instead of Ingress.
1. Add helm repository and configure Ingress
First of all, add helm repository:
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
helm repo updateCreate configuration file with ingress-nginx-values.yaml.
Then, install NGINX Ingress:
helm install ingress-nginx ingress-nginx/ingress-nginx
--namespace ingress-nginx
--create-namespace
-f ingress-nginx-values.yaml
--waitWait for LoadBalancer IP. The external IP assignment should take 1-2 minutes.
kubectl get svc -n ingress-nginx ingress-nginx-controller -wOnce <EXTERNAL-IP> is no longer , Ctrl+C and export it:
export EXTERNAL_IP=<EXTERNAL-IP>
echo "API URL: http://$EXTERNAL_IP"2. Create vLLM Ingress resource
Next, create vLLM Ingress using vllm-ingress.yaml.
Apply it as follow:
kubectl apply -f vllm-ingress.yamlYou can now test different API calls to verify that your deployment is functional.
3. Test API
Firstly, check if the model is available:
curl http://$EXTERNAL_IP/v1/models | jq{
"object": "list",
"data": [
{
"id": "qwen3-vl-8b",
"object": "model",
"created": 1772472143,
"owned_by": "vllm",
"root": "Qwen/Qwen3-VL-8B-Instruct",
"parent": null,
"max_model_len": 8192,
"permission": [
{
"id": "modelperm-8fb35cdd3208b068",
"object": "model_permission",
"created": 1772472143,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
]
}
]
}Next, test inference using the following request:
curl http://$EXTERNAL_IP/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model": "qwen3-vl-8b",
"messages": [{"role": "user", "content": "Count from 1 to 10."}],
"max_tokens": 100
}' | jq '.choices[0].message.content'"1, 2, 3, 4, 5, 6, 7, 8, 9, 10"
Great! You’re almost there…
Step 5 – Install Prometheus stack
Now, set up the monitoring stack that provides complete observability for application-level (vLLM) and hardware-level (GPU) metrics:
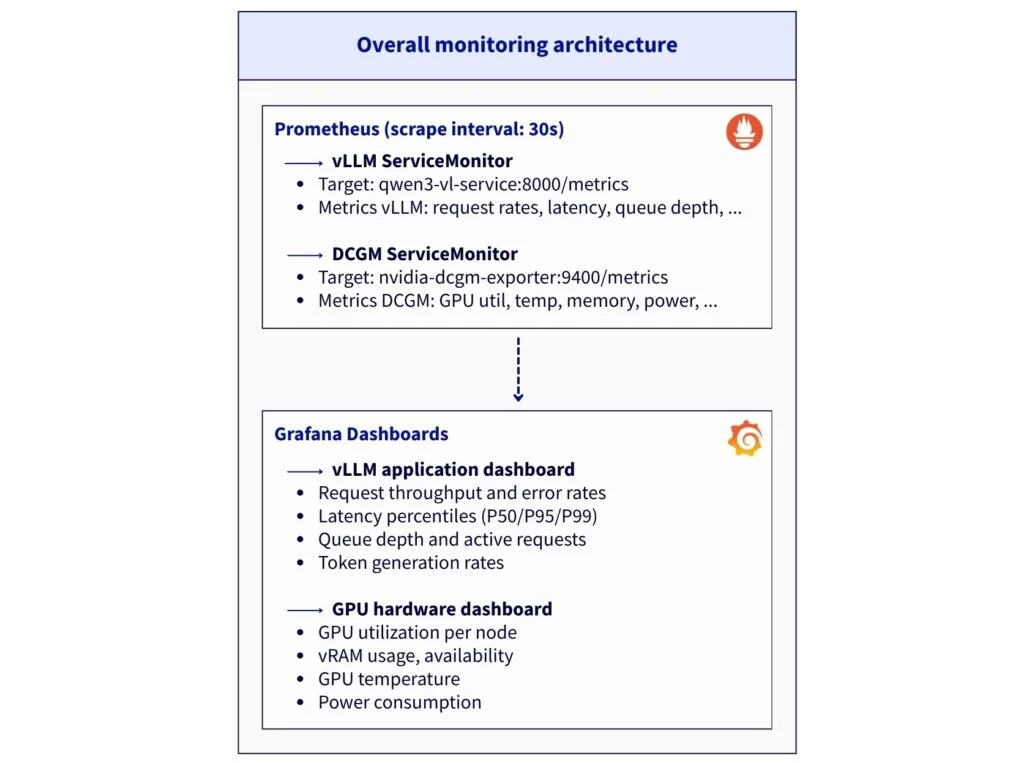
1. Add helm repository and create namespace
Add Prometheus helm repo:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo updateThen, create the monitoring Namespace.
kubectl create namespace monitoring2. Create Prometheus deployment configuration and installation
First, create prometheus.yaml file.
Install Prometheus stack:
helm install prometheus prometheus-community/kube-prometheus-stack
-n monitoring
-f prometheus.yaml
--timeout 10m
--waitNow, monitor its installation and wait until the pods are ready:
kubectl get pods -n monitoring -wIf all pods are running successfully, you can proceed to the next step.
3. Check that the installation is operational
First access Grafana in background:
kubectl port-forward -n monitoring svc/prometheus-grafana 3000:80 &Test Grafana health:
curl -s http://localhost:3000/api/health | jq{
"database": "ok",
"version": "12.3.3",
"commit": "2a14494b2d6ab60f860d8b27603d0ccb264336f6"
}You can now access to Grafana locally via http://localhost:3000. You will have to use:
- Login:
admin - Password:
Admin123!vLLM
Well done! You can now proceed to the configuration step.
Шаг 6 — Настройка ServiceMonitor
ServiceMonitor используется для указания Prometheus, с каких конечных точек собирать метрики.
1. Создание ServiceMonitor для vLLM
Получите файл из репозитория GitHub: vllm-servicemonitor.yaml.
Затем примените его и проверьте, что ServiceMonitor vllm-metrics существует:
kubectl apply -f vllm-servicemonitor.yaml
kubectl get servicemonitor -n vllm2. Создание ServiceMonitor для DCGM
Сначала создайте файл dcgm-servicemonitor.yaml.
Снова примените и проверьте:
kubectl apply -f dcgm-servicemonitor.yaml
kubectl get servicemonitor -n gpu-operatorgpu-operator 1d
nvidia-dcgm-exporter 1d
nvidia-node-status-exporter 1d3. Настройка Prometheus для обнаружения в разных пространствах имён
Примените патч, чтобы разрешить Prometheus обнаруживать ServiceMonitor во всех пространствах имён.
kubectl patch prometheus prometheus-kube-prometheus-prometheus -n monitoring --type merge -p '{
"spec": {
"serviceMonitorNamespaceSelector": {},
"podMonitorNamespaceSelector": {}
}
}'Теперь необходимо перезапустить Prometheus.
- Удалите под Prometheus, чтобы принудительно перезагрузить конфигурацию
- Дождитесь перезапуска Prometheus
kubectl delete pod prometheus-prometheus-kube-prometheus-prometheus-0 -n monitoring
kubectl wait --for=condition=Ready
pod/prometheus-prometheus-kube-prometheus-prometheus-0
-n monitoring
--timeout=180sПодождите около 2 минут для обнаружения и, наконец, проверьте цели:
kubectl port-forward -n monitoring
prometheus-prometheus-kube-prometheus-prometheus-0 9090:9090 &Вы можете открыть в браузере: http://localhost:9090/targets и найти:
vllmdcgm
Обратите внимание, что ожидаемые цели:
- serviceMonitor/vllm/vllm-metrics/0 (2/2 UP)
- serviceMonitor/gpu-operator/nvidia-dcgm-exporter/0 (2/2 UP)
Шаг 7 — Создание дашбордов Grafana
В этом последнем шаге цель — создать два дашборда Grafana для отслеживания как программной стороны с метриками vLLM, так и аппаратных метрик, которые будут мониторить потребление GPU и системы.
1. Метрики приложения vLLM
Дашборд предоставляет информацию о производительности приложения vLLM, обработке запросов и использовании ресурсов на основе следующих метрик:
| Метрика | Тип | Описание | Единица | Использование в дашборде |
|---|---|---|---|---|
vllm:request_success_total | Счётчик | Всего успешных запросов | кол-во | Скорость запросов, Всего запросов |
vllm:num_requests_running | Измеритель | Запросы, обрабатываемые в данный момент | кол-во | Глубина очереди, Активные запросы |
vllm:num_requests_waiting | Измеритель | Запросы, ожидающие в очереди | кол-во | Глубина очереди, Запросы в очереди |
vllm:time_to_first_token_seconds | Гистограмма | Задержка до генерации первого токена | секунды | TTFT P50/P95/P99 |
vllm:e2e_request_latency_seconds | Гистограмма | Общая сквозная задержка | секунды | Сквозная задержка P50/P95/P99 |
vllm:generation_tokens_total | Счётчик | Всего сгенерированных токенов (вывод) | кол-во | Скорость генерации токенов, Пропускная способность |
vllm:prompt_tokens_total | Счётчик | Всего токенов промпта (ввод) | кол-во | Скорость генерации токенов, Среднее кол-во токенов |
vllm:kv_cache_usage_perc | Измеритель | Использование кэша KV на GPU | 0-1 (0-100%) | Использование кэша KV |
vllm:prefix_cache_hits_total | Счётчик | Количество попаданий в кэш префиксов | кол-во | Коэффициент попаданий в кэш |
vllm:prefix_cache_queries_total | Счётчик | Количество запросов к кэшу префиксов | кол-во | Коэффициент попаданий в кэш |
vllm:request_queue_time_seconds | Гистограмма | Время ожидания в очереди | секунды | Время в очереди запросов |
vllm:request_prefill_time_seconds | Гистограмма | Время фазы предзаполнения | секунды | Время предзаполнения |
vllm:request_decode_time_seconds | Гистограмма | Время фазы декодирования | секунды | Время декодирования |
vllm:inter_token_latency_seconds | Гистограмма | Задержка между каждым токеном | секунды | Межтокенная задержка |
vllm:num_preemptions_total | Счётчик | Количество вытеснений (OOM) | кол-во | Вытеснения |
vllm:prompt_tokens_cached_total | Счётчик | Токены промпта, сохранённые в кэше | кол-во | Токены в кэше |
vllm:request_prompt_tokens | Гистограмма | Распределение размера промпта | кол-во | (Таблица) |
vllm:request_generation_tokens | Гистограмма | Распределение сгенерированных токенов | кол-во | (Таблица) |
vllm:iteration_tokens_total | Гистограмма | Токенов за итерацию | кол-во | (Расширенный анализ) |
Этот дашборд Grafana для vLLM состоит из 23 панелей:
Дашборд предоставляет информацию о производительности LLM-приложения, обработке запросов и использовании ресурсов на основе предыдущих метрик.
| Тип | Количество | Панели |
|---|---|---|
| Временной ряд | 12 | Скорость запросов, Глубина очереди, TTFT, Сквозная задержка, Генерация токенов, Использование кэша, Попадания в кэш, Время в очереди, Предзаполнение/Декодирование, Межтокенная задержка, Вытеснения, Среднее кол-во токенов |
| Статистика | 10 | Пропускная способность, TTFT P95, Активные запросы, Запросы в очереди, Коэффициент попаданий в кэш, Использование кэша, Всего запросов, Всего токенов, Токены в кэше, Вытеснения |
| Таблица | 1 | Производительность подов |
Теперь создайте дашборд, используя vllm-app-dashboard.json. Затем запустите:
echo "Importing vLLM application dashboard..."
curl -X POST
'http://localhost:3000/api/dashboards/db'
-H 'Content-Type: application/json'
-u 'admin:Admin123!vLLM'
-d @vllm-app-dashboard.json | jq '.status, .url'Затем вы можете получить доступ к дашборду vLLM и отслеживать метрики в реальном времени:
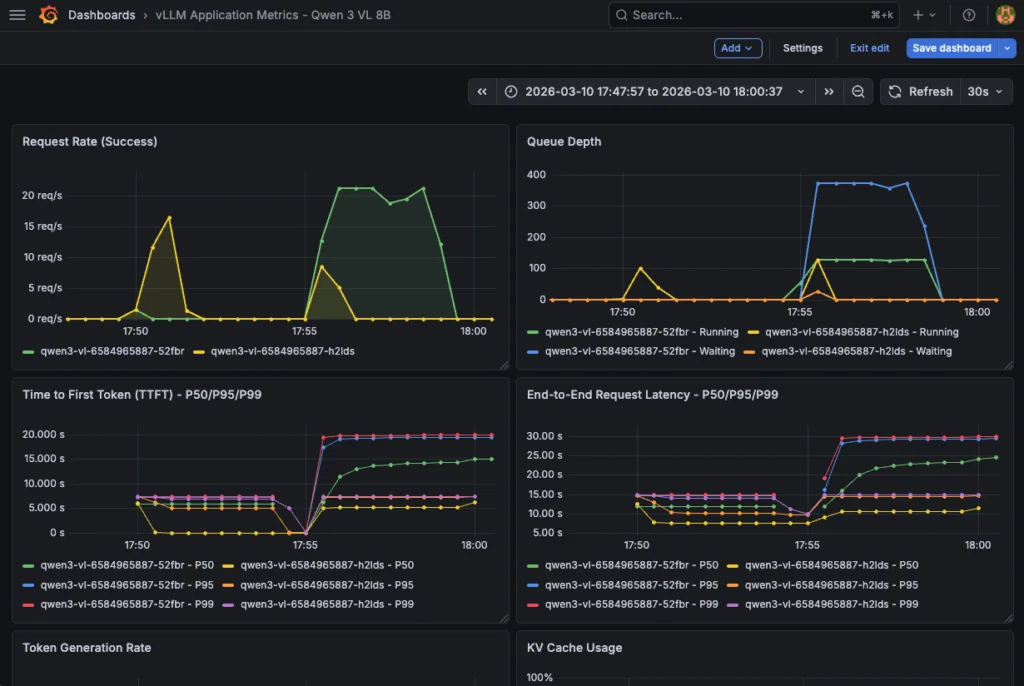
Этот дашборд также необходим для отслеживания потребления аппаратных ресурсов в рамках комплексного мониторинга.
2. Аппаратные метрики GPU
Используйте наиболее полезные метрики DCGM, чтобы проверить как работу, так и потребление ваших аппаратных ресурсов:
| Метрика | Тип | Описание | Единица измерения | Нормальные пороги | Использование в дашборде |
|---|---|---|---|---|---|
DCGM_FI_DEV_GPU_UTIL | Gauge | Использование GPU (вычисления) | % (0-100) | 70-95% оптимально | Использование GPU |
DCGM_FI_DEV_GPU_TEMP | Gauge | Температура GPU | °C | < 85°C нормально | Температура GPU |
DCGM_FI_DEV_FB_USED | Gauge | Использовано VRAM | МБ | Зависит от модели | Использовано памяти GPU |
DCGM_FI_DEV_FB_FREE | Gauge | Свободно VRAM | МБ | > 2 ГБ рекомендуется | Свободно памяти GPU |
DCGM_FI_DEV_POWER_USAGE | Gauge | Потребление энергии | Вт | < 300 Вт (L40S) | Использование питания GPU |
DCGM_FI_DEV_SM_CLOCK | Gauge | Тактовая частота GPU (вычисления) | МГц | Переменная | Тактовая частота GPU |
DCGM_FI_DEV_MEM_CLOCK | Gauge | Тактовая частота памяти | МГц | Переменная | Тактовая частота памяти |
DCGM_FI_DEV_NVLINK_BANDWIDTH_TOTAL | Counter | Общая пропускная способность NVLink | байт/с | (При использовании нескольких GPU) | Пропускная способность NVLink |
DCGM_FI_DEV_PCIE_TX_BYTES | Counter | Передано данных по PCIe | байты | (Мониторинг ввода-вывода) | PCIe TX |
DCGM_FI_DEV_PCIE_RX_BYTES | Counter | Получено данных по PCIe | байты | (Мониторинг ввода-вывода) | PCIe RX |
DCGM_FI_DEV_ECC_DBE_VOL_TOTAL | Counter | Двухбитные ошибки ECC | кол-во | 0 идеально | (Проверка здоровья) |
DCGM_FI_DEV_ECC_SBE_VOL_TOTAL | Counter | Однобитные ошибки ECC | кол-во | < 10/день допустимо | (Проверка здоровья) |
Этот аппаратный дашборд Grafana состоит из 13 панелей с метриками аппаратного обеспечения GPU и системы. Также доступен детальный просмотр использования GPU (%), температуры (°C), vRAM (ГБ) и питания (Вт).
| Тип | Количество | Панели |
|---|---|---|
| Timeseries | 8 | Использование GPU, Память GPU, Температура GPU, Питание GPU, Использование CPU, Использование RAM, Сетевой ввод-вывод, Дисковый ввод-вывод |
| Stat | 4 | Среднее использование GPU, Средняя температура GPU, Общая память GPU, Общее питание GPU |
| Table | 1 | Статус аппаратного обеспечения |
Пожалуйста, обратитесь к hardware-dashboard.json, загрузив его следующим образом:
echo "Импорт аппаратного дашборда..."
curl -X POST
'http://localhost:3000/api/dashboards/db'
-H 'Content-Type: application/json'
-u 'admin:Admin123!vLLM'
-d @hardware-dashboard.json | jq '.status, .url'Наконец, отслеживайте потребление ресурсов с помощью этого аппаратного дашборда:
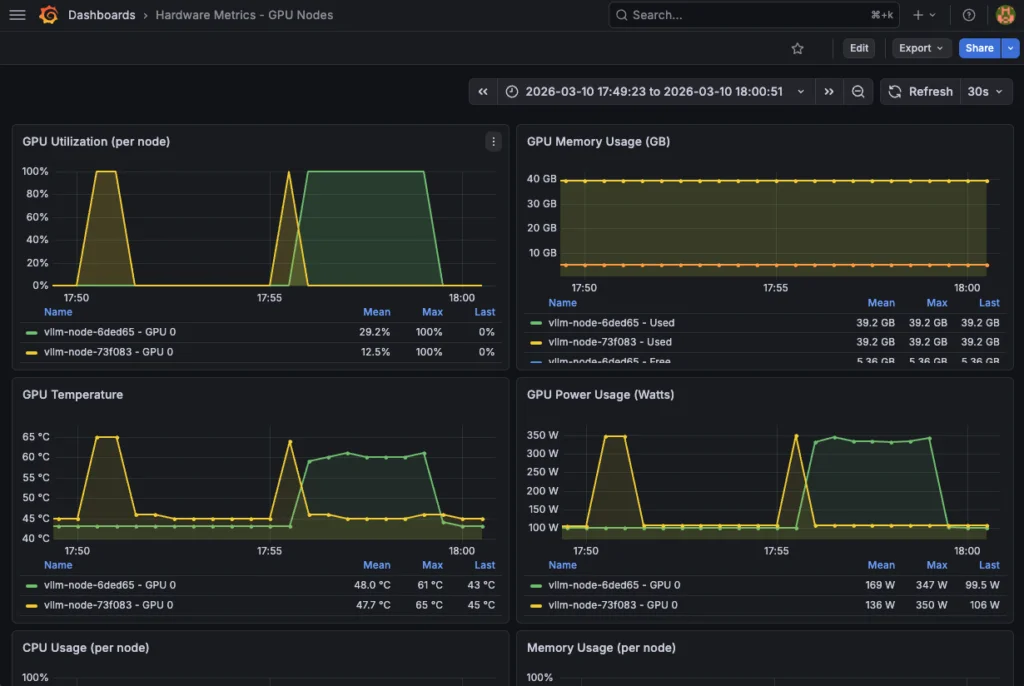
Поздравляем! Всё работает. Теперь вы можете протестировать свою модель и отслеживать различные метрики в реальном времени.
Шаг 8 — Тестирование LLM и отслеживание производительности
Начните с установки зависимостей Python:
pip3 install openai tqdmЗамените <EXTERNAL_IP> на внешний IP-адрес сервиса vLLM и запустите тест производительности с помощью следующего кода на Python:
import time
import threading
import random
from statistics import mean
from openai import OpenAI
from tqdm import tqdm
APP_URL = "http://94.23.185.22/v1"
MODEL = "qwen3-vl-8b"
CONCURRENT_WORKERS = 500 # параллелизм
REQUESTS_PER_WORKER = 10
MAX_TOKENS = 200 # нагрузка на генерацию
# несколько случайных промптов
SHORT_PROMPTS = [
"Обобщи теорию относительности.",
"Объясни, что такое трансформерная модель.",
"Что такое автомасштабирование в Kubernetes?"
]
MEDIUM_PROMPTS = [
"Объясни, как работают механизмы внимания в трансформерных моделях, включая self-attention и multi-head attention.",
"Опиши, как vLLM управляет KV-кэшем и почему это влияет на производительность инференса."
]
LONG_PROMPTS = [
"Напиши очень подробное техническое объяснение того, как большие языковые модели выполняют инференс, "
"включая токенизацию, поиск эмбеддингов, трансформерные слои, вычисление внимания, использование KV-кэша, "
"управление памятью GPU и то, как батчинг влияет на задержку и пропускную способность. Используй примеры.",
]
PROMPT_POOL = (
SHORT_PROMPTS * 2 +
MEDIUM_PROMPTS * 4 +
LONG_PROMPTS * 6 # смещение в сторону длинных промптов
)
# совместимость с openai
client = OpenAI(
base_url=APP_URL,
api_key="foo"
)
# базовые метрики
latencies = []
errors = 0
lock = threading.Lock()
# рабочий поток
def worker(worker_id):
global errors
for _ in range(REQUESTS_PER_WORKER):
prompt = random.choice(PROMPT_POOL)
start = time.time()
try:
client.chat.completions.create(
model=MODEL,
messages=[{"role": "user", "content": prompt}],
max_tokens=MAX_TOKENS,
temperature=0.7,
)
elapsed = time.time() - start
with lock:
latencies.append(elapsed)
except Exception as e:
with lock:
errors += 1
# запуск
threads = []
start_time = time.time()
print("n-> ЗАПУСК ТЕСТА ПРОИЗВОДИТЕЛЬНОСТИ:")
print(f"Параллелизм: {CONCURRENT_WORKERS}")
print(f"Всего запросов: {CONCURRENT_WORKERS * REQUESTS_PER_WORKER}")
for i in range(CONCURRENT_WORKERS):
t = threading.Thread(target=worker, args=(i,))
t.start()
threads.append(t)
for t in threads:
t.join()
total_time = time.time() - start_time
# результаты
print("n-> РЕЗУЛЬТАТЫ ТЕСТА:")
print(f"Всего отправлено запросов: {len(latencies) + errors}")
print(f"Успешных запросов: {len(latencies)}")
print(f"Ошибок: {errors}")
print(f"Общее время выполнения: {total_time:.2f}с")
if latencies:
print(f"Средняя задержка: {mean(latencies):.2f}с")
print(f"Минимальная задержка: {min(latencies):.2f}с")
print(f"Максимальная задержка: {max(latencies):.2f}с")
print(f"Пропускная способность: {len(latencies)/total_time:.2f} запр/с")Возвращая:
-> ЗАПУСК ТЕСТА ПРОИЗВОДИТЕЛЬНОСТИ:Параллелизм: 500
Всего запросов: 5000
-> РЕЗУЛЬТАТЫ ТЕСТА:
Всего отправлено запросов: 5000
Успешных запросов: 5000
Ошибок: 0
Общее время выполнения: 225.54с
Средняя задержка: 21.45с
Минимальная задержка: 6.06с
Максимальная задержка: 25.19с
Пропускная способность: 22.17 запр/с
Не забудьте отслеживать метрики GPU и vLLM в своих дашбордах Grafana!
Заключение
Эта эталонная архитектура демонстрирует развертывание vLLM в OVHcloud Managed Kubernetes Service (MKS) с комплексным мониторингом GPU. Преимущества включают:
- Высокая производительность: Инференс с ускорением на GPU (L40S)
- Масштабируемость: Нативная для Kubernetes, готова к горизонтальному масштабированию
- Надежность: Проверки здоровья, автоматический перезапуск, мониторинг
- Совместимость API: Эндпоинты, совместимые с OpenAI
- Мультимодальность: Возможности для работы с изображениями и текстом
- Полный стек мониторинга: Полноценные дашборды для приложения vLLM и аппаратного обеспечения
Дальнейшие шаги
Ваша текущая архитектура функциональна. Однако при желании её можно улучшить до полноценного решения, готового к промышленной эксплуатации.
Хотите сделать следующий шаг в усилении для продакшена?
Пойдите дальше с помощью следующих улучшений:
- Аутентификация и авторизация
- Аутентификация API vLLM
- Аутентификация Grafana
- Безопасность Prometheus
- Высокая доступность и балансировка нагрузки
- Высокая доступность Grafana с несколькими репликами и общим хранилищем
- Высокая доступность Prometheus
- Горизонтальное автомасштабирование подов (HPA) для vLLM на основе пользовательских метрик
- Сохраняемость данных и резервное копирование
- Долгосрочное хранение данных Prometheus с использованием постоянного хранилища
- Резервное копирование дашбордов Grafana
- Улучшения наблюдаемости
- Распределённая трассировка путём добавления OpenTelemetry для отслеживания запросов
- Правила оповещений с готовыми для продакшена алерт-правилами

Комментарии
Категории
Случайное
Защита корпоративной почты от спама:
