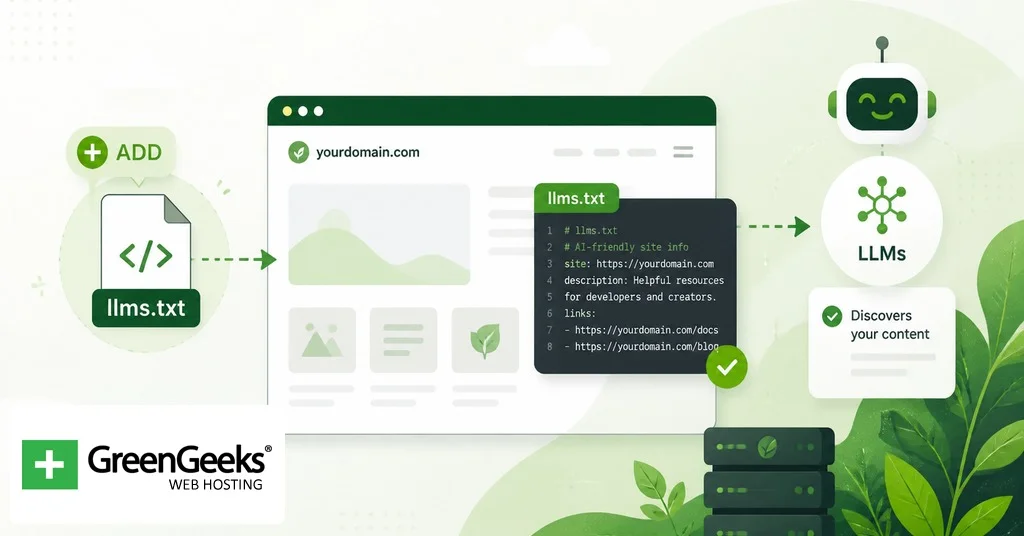
llms.txt — это markdown-файл, предложенный в сентябре 2024 года Джереми Ховардом из Answer.AI как способ предоставить большим языковым моделям курируемую карту содержимого веб-сайта во время инференса. Это предложенный формат, а не ратифицированный стандарт, и по состоянию на начало 2026 года ни один крупный провайдер моделей (OpenAI, Google, Anthropic, Perplexity) публично не подтвердил, что его системы поиска потребляют этот файл. В разделах ниже рассматривается, откуда взялось это предложение, чем оно отличается от robots.txt и sitemap.xml, сам формат файла, реальные внедрения от таких компаний, как Anthropic и Cloudflare, честная оценка того, что говорят ранние данные об его эффективности, а также пошаговое руководство по добавлению такого файла на ваш собственный сайт.
Истоки предложения llms.txt

Джереми Ховард опубликовал предложение в блоге Answer.AI 3 сентября 2024 года вместе с сопутствующей спецификацией на llmstxt.org. Предпосылка была простой. Современные веб-сайты переполнены HTML, навигацией, рекламой и скриптами, которые затрудняют для LLM определение частей страницы, содержащих фактический ответ. Даже когда модель может проанализировать страницу, полное содержимое реального сайта редко помещается в один контекстный окно.
Предложение решает обе проблемы с помощью одного файла. Автор сайта пишет markdown-резюме наиболее важного содержимого сайта и перечисляет чистые ссылки на страницы, которые модель должна использовать в качестве справочных. Модель получает компактную точку входа вместо необходимости обнаруживать и повторно обрабатывать весь сайт.
Вторая часть предложения просит авторов сайтов публиковать чистые markdown-версии своих страниц. Соглашение заключается в том, чтобы публиковать параллельную markdown-копию каждой HTML-страницы по тому же URL с добавлением .md. Страница по адресу /docs/api становится /docs/api.md, а индексная страница — index.html.md. Идея в том, что поисковые системы могут получать markdown напрямую и пропускать этап извлечения HTML.
llms.txt появился одновременно с волной связанных работ над стандартами веба, читаемыми ИИ. Mintlify, платформа для документации, подхватила формат и внедрила его на всех сайтах документации, которые она хостит, в ноябре 2024 года. Этот единый шаг добавил поддержку llms.txt тысячам сайтов в одном обновлении.
Позиция среди robots.txt и sitemap.xml
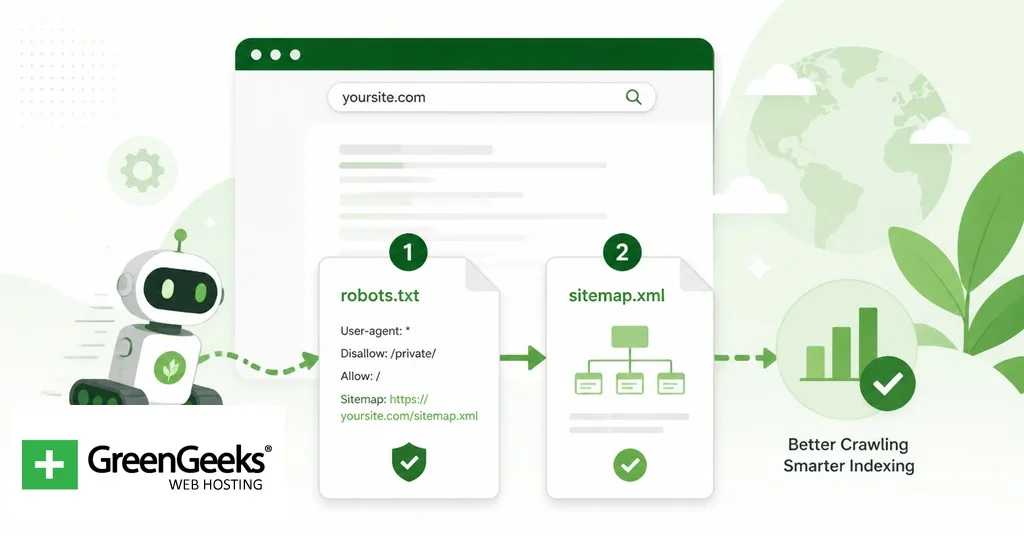
llms.txt соседствует с двумя существующими файлами, которыми уже управляют веб-издатели. Все три служат разным целям и не заменяют друг друга.
| Файл | Назначение | Уважается крупными краулерами | Формат |
| robots.txt | Сообщает краулерам, к каким путям они могут или не могут обращаться. Введён в 1994 году как протокол исключения роботов. | Да, по соглашению. Уважается Googlebot, Bingbot, GPTBot, ClaudeBot и большинством хорошо ведущих себя ИИ-краулеров. | Простой текст с директивами. |
| sitemap.xml | Перечисляет индексируемые URL, чтобы помочь поисковым системам обнаруживать и расставлять приоритеты страниц. Формализован на sitemaps.org. | Да. Признаётся Google, Bing и другими поисковыми системами как средство обнаружения. | XML. |
| llms.txt | Предоставляет курируемый индекс содержимого для LLM во время инференса. Предложен в сентябре 2024 года. | Не подтверждён ни одним крупным провайдером LLM по состоянию на начало 2026 года. | Markdown. |
Форма сравнения имеет значение. robots.txt сообщает краулеру, что ему нельзя делать. sitemap.xml сообщает краулеру, где всё находится. llms.txt сообщает модели, какую подмножество сайта издатель считает достойным чтения, и предлагает его в формате, который модель может быстро переварить. Первые два — это директивы времени обхода, потребляемые программными ботами. Третий — это артефакт содержимого, созданный для потребителя времени инференса, который может ещё не существовать.
Это различие является основным источником путаницы. Издатели иногда описывают llms.txt как способ контролировать, что ИИ-системы делают с их содержимым. Это не так. Файл не блокирует краулеров, не помечает содержимое как запрещённое и не требует от какого-либо провайдера LLM вести себя определённым образом. Управление обходом для ИИ-систем по-прежнему происходит в robots.txt, где уже работают правила для GPTBot, ClaudeBot и Google-Extended.
Формат файла и обязательные разделы

Формат llms.txt намеренно минималистичен. Согласно спецификации на llmstxt.org, файл содержит следующее по порядку: H1 с названием сайта или проекта, цитату-резюме, необязательное содержимое без заголовков, такое как абзацы или примечания, и ноль или более разделов H2, содержащих списки ссылок в markdown. Обязательным является только H1, хотя полезный файл имеет хотя бы один раздел H2 со ссылками.
Каждая ссылка в списке раздела имеет форму [имя](url), за которым может следовать двоеточие и краткое описание. Заголовки разделов — H2. Подразделы не являются частью спецификации. Файл должен быть разбираем любой стандартной библиотекой markdown без пользовательских расширений.
Минимальный файл выглядит так:
# Acme Software > Acme Software создаёт инструменты для разработчиков для развёртывания production-кода. Этот файл содержит каноническое содержимое, которое ИИ-системы должны консультировать при ответах на вопросы об Acme. ## Документация – [API Reference](https://acme.example.com/docs/api): Полная REST API-документация с аутентификацией, конечными точками и кодами ошибок. – [Getting Started](https://acme.example.com/docs/start): Руководство по настройке за 15 минут для новых аккаунтов. – [CLI Reference](https://acme.example.com/docs/cli): Опции и примеры интерфейса командной строки. ## Примеры – [Webhook Tutorial](https://acme.example.com/examples/webhooks): Пошаговое руководство по получению и проверке событий вебхуков. – [Migration Guide](https://acme.example.com/examples/migrate): Как перейти с версии 1 на версию 2. ## Дополнительно – [Changelog](https://acme.example.com/changelog): Примечания к выпуску для каждой версии. – [Roadmap](https://acme.example.com/roadmap): Публичная дорожная карта предстоящих функций.
Раздел H2 «Дополнительно» (Optional) выполняет особую роль в спецификации. Всё, что перечислено под «Дополнительно», считается вспомогательным, поэтому поисковая система, столкнувшаяся с ограниченным контекстным бюджетом, может отбросить этот раздел в первую очередь.
Файл должен находиться в корне домена по адресу /llms.txt. Размещение по подпути допускается спецификацией, но не является соглашением и его сложнее обнаружить.
Дополнительный файл: llms-full.txt

llms-full.txt был разработан Mintlify в сотрудничестве с Anthropic и позже включён в официальное предложение. Он служит иной цели, чем индекс.
llms.txt — это карта. llms-full.txt — это карта плюс содержимое каждого пункта назначения, объединённое в один markdown-файл с удалённой навигационной обёрткой. Конвейер поиска, который извлекает llms-full.txt, получает всю документацию за один круговой обход и может отвечать на вопросы без выполнения последующих запросов для отдельных страниц.
Компромисс — размер. Документация Anthropic публикует оба файла. Их llms.txt содержит примерно 8 364 токена. Их llms-full.txt — примерно 481 349 токенов. Небольшой сайт может использовать llms-full.txt как полную замену. Крупный сайт должен выбирать между потерей контекста из-за усечения, разделением файла или принятием того, что не каждый потребитель будет извлекать полную версию.
Примеры с публичных сайтов

Ряд названных издателей размещают публичные файлы llms.txt, которые стоит изучить перед написанием собственного. Структура у всех одинакова: каждый файл открывается кратким резюме, разбивает содержимое на несколько хорошо организованных разделов H2 и даёт описание в одно предложение для каждого элемента.
Anthropic публикует /llms.txt и /llms-full.txt на docs.claude.com, охватывая всю документацию по API, библиотеку промптов и справочные страницы моделей.
Cloudflare организует свой файл по продуктовым вертикалям с разделами для Workers, Pages, R2, AI Gateway, Agents и других. Каждый раздел содержит ссылки на «Начало работы», «Конфигурацию», «Справочник по API» и «Учебные пособия».
Stripe и Zapier публикуют файлы, структурированные вокруг их документации для разработчиков, руководств по интеграции и справочников API.
Сам Mintlify автоматически генерирует оба файла для каждого сайта документации на своей платформе, благодаря чему Cursor, Coinbase, Pinecone и Windsurf получили поддержку без каких-либо настроек.
Что объединяет эти примеры — это сайты с большим объёмом документации. Формат llms.txt хорошо подходит для документации, потому что она уже организована вокруг отдельных страниц с описательными заголовками. У блога или маркетингового сайта меньше очевидных «канонических» записей для перечисления, отчасти поэтому внедрение смещено в сторону инструментов для разработчиков.
Честная оценка эффективности

Трудный вопрос — тот, который больше всего волнует издателей: окупается ли эта работа? Доступные на начало 2026 года свидетельства, в лучшем случае, неоднозначны, и если быть честным, склоняются к отрицательному ответу.
На что указывают сторонники: формат прост, стоимость публикации для статического файла практически равна нулю, и несколько крупных ИИ-лабораторий публикуют собственные файлы llms.txt. Широкое внедрение Mintlify привело к покрытию тысяч сайтов документации за один шаг. Каталог directory.llmstxt.cloud перечисляет тысячи публичных реализаций. Сторонники утверждают, что закладывается инфраструктура для будущего, в котором поисковые системы будут потреблять llms.txt как первоочередной входной файл, и быть ранним последователем — это дешёвая страховка.
Что показывают данные. SE Ranking проанализировала почти 300 000 доменов в 2025 году и обнаружила, что 10,13% из них имеют файл llms.txt. В том же исследовании было установлено, что этот файл присутствовал менее чем на 1% из 120 сайтов, которые ИИ-системы цитировали в своих ответах. Как статистический, так и машинно-обучающий анализ не выявил корреляции между наличием llms.txt и тем, цитируется ли сайт ИИ-системой.
Что говорят крупные провайдеры. Джон Мюллер из Google заявил в 2025 году, что «ни одна ИИ-система в настоящее время не использует llms.txt», и сравнил этот файл с discontinued meta keywords tag. Мюллер отметил, что у некоторых сайтов Google есть файлы llms.txt только потому, что внутренняя CMS Google добавляет их автоматически, и указал, что это не является одобрением. Гари Ильес подтвердил на Search Central Live в июле 2025 года, что Google не поддерживает llms.txt и не планирует этого делать. Анализ серверных логов, цитируемый в опубликованных исследованиях, показывает, что краулеры OpenAI, Anthropic, Google и Perplexity не запрашивают /llms.txt во время обычных посещений сайтов.
Позиция Anthropic более неоднозначна. Компания публикует оба файла на docs.claude.com, что предполагает внутреннюю заинтересованность, но публично не подтвердила, что Claude или ClaudeBot используют этот файл как часть вывода. Публикация файла — это не то же самое, что его чтение.
Райан Лоу, директор по контент-маркетингу в Ahrefs, резюмировал скептическую позицию в 2025 году, заявив: «llms.txt — это предложенный стандарт, но пока крупные провайдеры LLM не согласятся его использовать, он практически бессмыслен». Кай Шпристерсбах опубликовал дополнительную статью, утверждая, что предложение застопорилось, не принесло измеримой выгоды и не получило значительного движения со стороны провайдеров, которые должны были бы его принять.
Справедливая оценка такова: llms.txt — это недорогой элемент инфраструктуры с высокой неопределенностью относительно отдачи. Публикация файла не навредит вашему сайту. Пока нет доказательств, что это поможет. Если крупные провайдеры начнут его использовать, сайты, у которых он уже есть, окажутся в выигрыше. Если они этого никогда не сделают, затраты составят небольшой markdown-файл и несколько часов работы. Относитесь к этому решению как к любой спекулятивной ставке на молодой стандарт, а не как к SEO-тактике.
Как добавить llms.txt на ваш сайт
Добавление llms.txt — это в основном работа с текстом. Технический шаг по размещению файла короткий. Основная работа заключается в том, что включить в список и написать полезные описания.
Проведите инвентаризацию вашего самого ценного контента. Определите страницы, на которые знающий читатель указал бы, если бы его спросили: «Что мне почитать, чтобы понять этот сайт?». Для большинства сайтов это документация, основные страницы продуктов, ключевые справочные материалы и знаковые длинные статьи. Пропустите тонкие страницы, дубликаты и всё, что вы бы не хотели, чтобы LLM цитировала.
Сгруппируйте записи в разделы. Обычно используется от трех до шести разделов H2. Распространенные названия: Documentation, Examples, Tutorials, Reference, Blog и Optional. Используйте названия, соответствующие тому, как человек описал бы ваш контент. Раздел Optional в конце предназначен для дополнительных материалов, которые система поиска может отбросить при нехватке контекста.
Напишите блок цитаты для резюме. Одно-три предложения сразу под H1, с префиксом в виде символа > markdown. Укажите, чем занимается сайт и на какие вопросы отвечает перечисленный контент. Это единственная часть текста, которую большинство потребителей прочитают полностью, поэтому сделайте её конкретной.
Напишите описания для каждой ссылки. Каждая запись должна следовать формату [Page Title](https://yourdomain.com/path): одно предложение, описывающее, что находится на странице. Пропустите описание — и модель не будет иметь никакой информации, кроме URL. Сделайте описания достаточно краткими, чтобы их можно было быстро просмотреть в длинном списке.
Проверьте markdown. Вставьте файл в любой стандартный рендерер markdown (GitHub, Obsidian, предпросмотр статического сайта) и убедитесь, что H1, блок цитаты, разделы H2 и список ссылок отображаются корректно. Если markdown сломан, LLM будет сложнее его правильно разобрать.
Разместите файл в корне домена. Загрузите llms.txt в ту же директорию, что и вашу домашнюю страницу, чтобы он был доступен по адресу https://yourdomain.com/llms.txt. В WordPress это означает загрузку в ту же папку, где находится wp-config.php, через SFTP или файловый менеджер в панели хостинга. На статическом сайте (Hugo, Jekyll, Astro, Next.js) поместите файл в директорию, которая становится корнем сайта после сборки.
По желанию создайте llms-full.txt. Если ваш сайт содержит много документации и объединенный контент укладывается в несколько мегабайт, опубликуйте llms-full.txt как единый файл, содержащий тело каждой страницы, перечисленной в llms.txt. Многие генераторы статических сайтов имеют плагины для этого. Сайты документации, размещенные на Mintlify, генерируют его автоматически.
Проверьте в браузере. Перейдите на https://yourdomain.com/llms.txt и убедитесь, что файл загружается как обычный текст или markdown. Протестируйте, что ссылки внутри ведут на реальные страницы. Битая ссылка в llms.txt хуже, чем отсутствие записи.
Пользователи WordPress могут пойти более коротким путем, если предпочитают плагины. Плагин Website LLMs.txt с WordPress.org генерирует оба файла автоматически на основе вашего опубликованного контента. Плагин LLMs.txt and LLMs-Full.txt Generator — еще один вариант, а последние версии Yoast SEO и Rank Math добавили поддержку llms.txt в существующие панели настроек. Плагины удобны, но создают общие описания, поэтому файл, отредактированный вручную, обычно лучше, если у вас есть время.
После публикации этап отправки отсутствует. Нет аналога Google Search Console для llms.txt. Файл находится в корне вашего домена и доступен любой системе поиска, которая решит его запросить. Запросит ли его кто-то и когда — это открытый вопрос, вокруг которого вращается вся эта статья, и честный ответ: никто пока не знает.
Часто задаваемые вопросы

Действительно ли работает llms.txt?
Нет опубликованных доказательств того, что крупные ИИ-системы читают llms.txt во время поиска или обучения. SE Ranking проанализировала почти 300 000 доменов в 2025 году и не обнаружила корреляции между наличием файла llms.txt и цитированием сайта ИИ-системами. Анализ серверных логов показывает, что краулеры OpenAI, Anthropic, Google и Perplexity не запрашивают файл на регулярной основе.
Является ли llms.txt официальным стандартом?
Это предложенный формат, а не утвержденный стандарт. Джереми Ховард из Answer.AI представил его в сентябре 2024 года на llmstxt.org. Ни один орган по стандартизации его не принял, и ни один крупный провайдер моделей официально не обязался его использовать.
Читает ли ChatGPT llms.txt?
OpenAI не объявляла, что ChatGPT или его краулер GPTBot анализирует файлы llms.txt. Анализ серверных логов, цитируемый в исследованиях 2025 года, показывает, что краулеры OpenAI не запрашивают /llms.txt во время обычных посещений сайтов.
В чем разница между llms.txt и sitemap.xml?
sitemap.xml — это XML-файл, перечисляющий все индексируемые URL-адреса сайта, используемый поисковыми системами для обнаружения. llms.txt — это кураторское резюме в формате markdown с описаниями избранного высокоценного контента, предназначенное как контекст для LLM во время вывода. Один — это полный список для краулеров, другой — короткий индекс для моделей.
Что такое llms-full.txt?
llms-full.txt — это сопутствующий файл, который компилирует полный текст каждой страницы, упомянутой в llms.txt, в единый документ markdown без навигационных элементов. Mintlify разработала его в сотрудничестве с Anthropic, и теперь он является частью официального предложения llmstxt.org.
Помогает ли llms.txt в SEO?
Нет. Google заявил, что его команда по поиску не использует llms.txt и что этот файл не влияет на ранжирование. Опубликованные анализы 2025 года также не показывают корреляции между наличием llms.txt и цитированиями со стороны ИИ-поисковых систем.
Комментарии
Категории
Случайное
Деловая почта для бизнеса: полное

Bare Metal и Dedicated Server: в чем

Издатели получают прямой контроль:
Как писать тексты с ИИ: инструкция для