Если вам нужно больше информации о AI Endpoints, прочитайте следующую запись в блоге. Вы также можете посмотреть наши предыдущие записи в блоге о том, как использовать AI Endpoints.
Полный пример кода вы найдете в репозитории GitHub.
В этой статье мы рассмотрим, как выполнить OCR (оптическое распознавание символов) на изображениях с помощью LLM с поддержкой зрения, библиотеки OpenAI для Python и AI Endpoints от OVHcloud.
Введение в OCR с моделями зрения
Оптическое распознавание символов существует уже несколько десятилетий, но традиционные OCR-движки часто испытывают трудности со сложными макетами, рукописным текстом или зашумленными изображениями. Большие языковые модели с поддержкой зрения предлагают новый подход: вместо использования специализированных OCR-конвейеров вы можете просто отправить изображение модели, которая понимает как визуальный, так и текстовый контент.
В этом примере мы используем библиотеку OpenAI для Python, чтобы создать простой OCR-скрипт, работающий на основе модели зрения, размещенной на AI Endpoints от OVHcloud.
Все приложение представляет собой один файл Python: никакой сложной настройки, просто pip install openai, и вы готовы к работе.
Настройка переменных окружения
Перед запуском скрипта необходимо установить следующие переменные окружения:
export OVH_AI_ENDPOINTS_ACCESS_TOKEN="your-access-token"
export OVH_AI_ENDPOINTS_MODEL_URL="https://your-model-url"
export OVH_AI_ENDPOINTS_VLLM_MODEL="your-vision-model-name"Инструкции по созданию токена доступа, URL-адреса модели и имени модели можно найти в каталоге AI Endpoints. Убедитесь, что выбрали модель с поддержкой зрения из каталога AI Endpoints.
Установка зависимостей
Единственная зависимость — это библиотека OpenAI для Python:
pip install openaiОпределение системного промпта
Первый шаг — определить системный промпт, который описывает, что делает наша OCR-служба. Этот промпт указывает модели, как себя вести:
SYSTEM_PROMPT = """Вы — экспертный OCR-движок.
Извлеките каждый фрагмент текста, видимый на предоставленном изображении.
Максимально точно сохраните исходную структуру (разрывы строк, колонки, таблицы).
НЕ интерпретируйте, не суммируйте и не переводите содержимое.
Используйте форматирование Markdown для представления структуры (например, таблицы, списки).
Если на изображении нет текста, ответьте: "Текст не найден."
"""Мы указываем ему вести себя как экспертный OCR-движок, сохранять исходную структуру и использовать форматирование Markdown для структурированного контента, такого как таблицы или списки.
Загрузка изображения
Прежде чем отправить изображение модели, нам нужно закодировать его в строку base64. Вот простая вспомогательная функция, которая считывает локальный PNG-файл и возвращает строку в кодировке base64:
import base64
from pathlib import Path
def load_image_as_base64(path: Path) -> str:
"""Загрузить локальное изображение и закодировать его в base64."""
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")Данные в кодировке base64 — это то, что отправляется модели зрения как часть промпта.
Извлечение текста из изображения
Функция extract_text отправляет изображение модели зрения и возвращает извлеченный текст:
def extract_text(client: OpenAI, image_base64: str, model: str) -> str:
"""Извлечь текст из изображения с помощью модели зрения."""
response = client.chat.completions.create(
model=model,
temperature=0.0,
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{image_base64}"
}
}
]
}
]
)
return response.choices[0].message.contentИзображение передается как data URL внутри поля image_url, в соответствии с форматом OpenAI Vision API. Параметр temperature установлен на 0.0, потому что нам нужно детерминированное, точное извлечение текста, а не креативный вывод.
Настройка клиента
В этом примере используется модель с поддержкой зрения, размещенная на AI Endpoints от OVHcloud. Поскольку AI Endpoints предоставляет API, совместимый с OpenAI, мы используем клиент OpenAI и просто указываем ему на конечную точку OVHcloud:
import os
from openai import OpenAI
client = OpenAI(
api_key=os.getenv("OVH_AI_ENDPOINTS_ACCESS_TOKEN"),
base_url=os.getenv("OVH_AI_ENDPOINTS_MODEL_URL"),
)
model_name = os.getenv("OVH_AI_ENDPOINTS_VLLM_MODEL")Несколько важных моментов:
- API-ключ, базовый URL и имя модели считываются из переменных окружения.
- Библиотека OpenAI совместима с любым API, совместимым с OpenAI, что делает ее идеальной для использования с AI Endpoints.
Сборка и запуск
После настройки клиента извлечение текста из изображения становится простым:
image_base64 = load_image_as_base64(Path("./doc.png"))
result = extract_text(client, image_base64, model_name)
print(result)И это всё!
Вот изображение, использованное в этом примере:
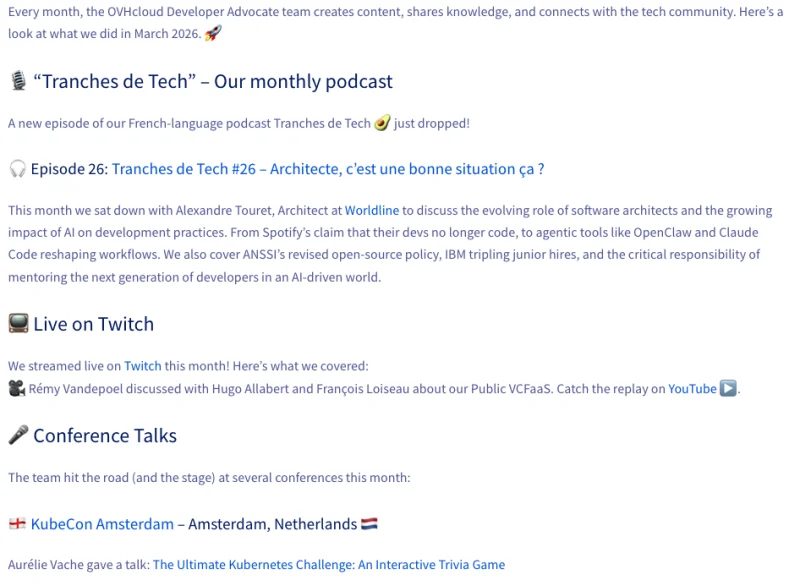
И результат:
$ python ocr_demo.py
📄 Загрузка изображения: doc.png
🔍 Запуск OCR с Qwen2.5-VL-72B-Instruct через OVHcloud AI Endpoints...
📝 Извлеченный текст 📝
Каждый месяц команда Developer Advocate OVHcloud создает контент, делится знаниями и общается с техническим сообществом. Вот что мы сделали в марте 2026 года. 🚀
🎙️ “Tranches de Tech” – Наш ежемесячный подкаст
Вышел новый эпизод нашего франкоязычного подкаста Tranches de Tech🥑!
🎧 Эпизод 102: Tranches de Tech #26 – Архитектор, это хорошая позиция?
В этом месяце мы пообщались с Александром Туре, архитектором в Worldline, чтобы обсудить меняющуюся роль архитекторов программного обеспечения и растущее влияние ИИ на практики разработки. От заявления Spotify о том, что их разработчики больше не пишут код, до агентных инструментов, таких как OpenClaw и Claude Code, меняющих рабочие процессы. Мы также освещаем пересмотренную политику ANSSI в отношении открытого исходного кода, утроение найма junior-специалистов в IBM и критическую важность наставничества для следующего поколения разработчиков в мире, управляемом ИИ.
📺 Прямые трансляции на Twitch
В этом месяце мы проводили прямые трансляции на Twitch! Вот что мы освещали:
🎥 Реми Вандепул обсудил с Юго Альябером и Франсуа Лозо наш Public VCFaaS. Смотрите повтор на YouTube ▶️.
🎤 Выступления на конференциях
Команда выступила на нескольких конференциях в этом месяце:
🇳🇱 KubeCon Amsterdam – Амстердам, Нидерланды 🇳🇱
Орели Ваш выступила с докладом: The Ultimate Kubernetes Challenge: An Interactive Trivia GameЗаключение
В этой статье мы рассмотрели, как использовать LLM с возможностью зрения для выполнения OCR на изображениях с помощью библиотеки OpenAI Python и OVHcloud AI Endpoints. Библиотека OpenAI делает очень простой отправку изображений в модель зрения и извлечение текста, а Python позволяет запустить всё в виде простого скрипта.
У вас есть специальный канал Discord (#ai-endpoints) на нашем Discord-сервере (https://discord.gg/ovhcloud), увидимся там!

Комментарии
Категории
Случайное

Serverless: где такой подход работает,
