Ключевые моменты
- Определяйте сигналы о снижении производительности, которые указывают на необходимость перезагрузки сервера для оптимальной работы.
- Распознавайте критические временные окна, чтобы избежать потери данных и перерывов в обслуживании во время процедуры перезагрузки.
- Выполняйте предварительные проверки перед перезагрузкой, чтобы обеспечить стабильность системы и минимизировать риски незапланированных простоев.
- Подтверждайте работоспособность системы после перезагрузки с помощью комплексной проверки служб и анализа журналов.
- Определяйте оптимальные сценарии для целевой перезагрузки служб в сравнении с полной перезагрузкой системы.
Системные администраторы сталкиваются с общей дилеммой при возникновении проблем с производительностью системы. Представьте это как перезагрузку вашего смартфона – все знают, что это помогает производительности, но выбор неподходящего момента может прервать важные задачи. Хотя перезагрузка может решить проблемы с утечкой памяти и обновить системные процессы, неправильное время её выполнения способно вызвать серьёзные нарушения в работе бизнеса.
Это подробное руководство поможет вам определить чёткие индикаторы того, когда сервер нужно перезагрузить, а когда лучше подойдут альтернативные решения. Вы научитесь распознавать предупреждающие признаки снижения производительности, избегать критических ошибок в выборе времени и выполнять безопасные процедуры перезапуска, которые защитят ваши данные и сведут к минимуму время простоя.
Почему перезагрузка сервера может устранить проблемы с производительностью?
Перезагрузка сервера эффективно решает несколько глубинных системных проблем, которые имеют свойство накапливаться в течение длительных периодов бесперебойной работы. Понимание этих механизмов позволяет администраторам принимать взвешенные решения о том, когда перезагрузка сервера строго необходима, а когда может хватить точечного устранения неполадок.
1. Утечки памяти и потребление ресурсов
Утечки памяти — основная причина, по которой перезагрузка серверов восстанавливает утраченную производительность. По мере работы приложений и процессов они постепенно потребляют системную память и зачастую не могут правильно освободить эти ресурсы для операционной системы. За недели или месяцы это постепенное потребление достигает критического уровня, что значительно ухудшает производительность. Перезагрузка системы решает эту проблему, полностью очищая выделенную память и возвращая сервер в исходное состояние ресурсов.
2. Проблемы с долго работающими процессами
Помимо проблем с памятью, долго работающие процессы со временем часто становятся неэффективными или повреждёнными. Фоновые службы могут начать испытывать проблемы с взаимодействием с другими компонентами, а временные данные накапливаются до такой степени, что влияют на общую скорость. Кроме того, подключения к базе данных могут устаревать или переставать отвечать, а процессы веб-сервера — зависать. Перезагрузка принудительно перезапускает эти демоны и службы, очищая временные данные и устанавливая новые рабочие соединения.
3. Ожидающие применения системные обновления
Наконец, системные обновления часто требуют перезагрузки для полного вступления в силу. Критически важные задачи обслуживания, такие как обновления ядра, патчи безопасности и установка драйверов, изменяют основные системные файлы, которые невозможно обновить, пока операционная система активна. Эти обновления остаются в состоянии ожидания до следующего цикла перезагрузки, который активирует новые конфигурации и загружает обновлённые системные компоненты, необходимые для безопасности и стабильности.
Понимание этих технических причин поможет вам оценить, решает ли перезагрузка ваши конкретные проблемы с производительностью, или же целевое устранение неполадок предложит лучшее решение для вашей серверной среды.
Теперь, когда вы понимаете, почему перезагрузки работают, следующий важный шаг — определить, когда вашему серверу она действительно нужна. Ваша система посылает чёткие предупреждающие сигналы, когда пришло время перезапуска, и раннее распознавание этих индикаторов предотвращает серьёзные простои и снижение производительности.
Топ-3 явных признака, что сервер нужно перезагрузить
Понимание того, когда следует перезагружать сервер, помогает предотвратить эскалацию незначительных проблем до серьёзных системных сбоев. Распознавание этих предупреждающих знаков на ранней стадии позволяет вам принять меры до того, как проблемы повлияют на ваших пользователей или операции.
Давайте рассмотрим три критических индикатора, которые сигнализируют, что пришло время перезагрузить ваш сервер.
1. Производительность постепенно снизилась
Постепенное снижение производительности часто указывает на системные проблемы, которые накапливаются со временем. Следите за ключевыми предупреждающими признаками, такими как постоянное увеличение времени отклика сервера при стабильной пользовательской нагрузке или тенденция к росту потребления памяти в течение нескольких дней или недель. Высокая средняя нагрузка на систему может возникать в периоды низкой активности, в то время как таймауты приложений и ошибки подключения становятся более частыми. Кроме того, запросы к базе данных, которые раньше выполнялись быстро, могут начать превышать время ожидания, а веб-приложения могут показывать периодические проблемы с загрузкой, которые временно решаются, но вскоре возвращаются.
Чтобы выявить эти проблемы, отслеживайте время отклика сервера в периоды обычной нагрузки, чтобы установить базовые измерения. Когда появляется устойчивая высокая нагрузка без соответствующих всплесков трафика, это говорит о том, что фоновые процессы потребляют чрезмерное количество ресурсов.
Помимо метрик производительности, стабильность на уровне служб представляет собой не менее убедительные сценарии для перезапуска.
2. Службы нестабильны или не отвечают
Нестабильность служб — явный показатель того, что перезагрузка системы может решить глубинные проблемы. Когда критические службы не могут чисто перезапуститься с помощью обычных административных команд, часто существуют более глубокие системные проблемы, которые может решить только полная перезагрузка.
Ищите характерные признаки нестабильности служб: административные панели и интерфейсы мониторинга отображают противоречивые данные или перестают отвечать; индикаторы состояния служб могут показывать конфликтующую информацию или некорректно обновляться. Также сильными индикаторами являются многократные неудачные попытки перезапуска служб через команды systemctl или service, а также неудачи в решении текущих проблем с помощью процедур перезапуска, специфичных для приложений.
Эти симптомы позволяют предположить, что компоненты системного мониторинга потеряли синхронизацию с фактическими состояниями служб или что процессы заблокировались или повредились. Когда базовое состояние системы требует полного обновления, стандартные процедуры перезапуска не сработают.
Наряду с реактивным устранением неполадок, плановое системное обслуживание создаёт запланированные возможности для необходимых перезагрузок.
3. Обновления или изменения системы требуют перезагрузки
Некоторые системные изменения не могут вступить в силу при обычной работе и требуют полного цикла перезапуска. Наиболее распространённые сценарии включают обновления ядра и патчи безопасности, которые изменяют основные системные компоненты, а также установку драйверов для аппаратных компонентов, требующих загрузки модулей ядра. Изменения конфигурации системы, касающиеся сетевых настроек, политик безопасности или основных служб, также часто требуют перезагрузки.
Эти обновления обычно отображают уведомления о необходимости перезагрузки в журналах системы или интерфейсах управления обновлениями. Отсрочка этих перезагрузок увеличивает воздействие уязвимостей безопасности и может вызвать общую нестабильность системы. Сетевым картам, контроллерам хранилищ и графическим адаптерам нужны полные циклы инициализации для правильной работы с обновлёнными драйверами.
Хотя некоторые обновления конфигурации вступают в силу немедленно, другим требуется полная инициализация системы для обеспечения надлежащей интеграции с существующими компонентами. Задержка этих перезагрузок может привести к сбою оборудования или снижению производительности.
Определив явные индикаторы перезагрузки, понимание того, когда следует избегать перезапусков, становится не менее важным для поддержания стабильности системы и предотвращения ненужных перерывов в обслуживании.
Когда НЕ следует перезагружать сервер?
Знание того, когда следует избегать перезагрузок сервера, предотвращает повреждение данных и минимизирует влияние на бизнес. Определённые рабочие состояния и системные условия делают перезагрузки особенно рискованными или контрпродуктивными.
Давайте рассмотрим конкретные сценарии, в которых выполнение перезагрузки может причинить больше вреда, чем пользы.
1. Во время активной записи или критических операций
Прерывание текущих операций может привести к серьёзной потере данных и нестабильности системы. Перед инициированием любого перезапуска вам следует проверить наличие этих критических процессов:
- Транзакции базы данных: Активные подключения к базе данных и долго выполняющиеся запросы подвержены риску повреждения при неожиданном выключении. Всегда дожидайтесь естественного завершения транзакций, прежде чем приступать к процедуре перезагрузки.
- Операции передачи файлов: Сессии FTP, операции rsync и загрузка больших файлов могут привести к повреждённым или неполным данным при прерывании системной перезагрузкой. Отслеживайте эти активные процессы и давайте им достаточно времени для завершения.
- Процедуры резервного копирования системы: Они требуют бесперебойной работы для обеспечения целостности данных. Перезагрузка во время операций резервного копирования может повредить файлы резервных копий или создать неполные архивы, которые нельзя будет правильно восстановить в сценариях аварийного восстановления.
Хотя выбор времени выполнения операций имеет решающее значение, понимание первопричины проблемы не менее важно для определения того, является ли перезагрузка правильным решением.
2. Когда проблема явно не является системной
Не все проблемы с сервером требуют перезагрузки. Фактически, перезагрузка не решит проблемы, которые происходят из других источников. Вот ситуации, в которых целевое устранение неполадок является более правильным подходом:
- Application-specific bugs: These require code fixes rather than system restarts. Analyze error logs to determine whether issues originate from application logic, database queries or external service dependencies.
- Network connectivity issues: Check network configuration, cable connections and hardware status indicators before assuming a system restart will resolve connectivity problems.
- External service dependencies: Verify third-party API availability, external database connections and remote service status. Reboots cannot fix problems that exist outside your server environment.
Once you’ve confirmed that a reboot is necessary through careful analysis of system conditions, proper timing becomes essential.
3. During peak traffic or production windows
The timing of server restarts can significantly impact your business operations and user experience. Consider these factors when scheduling maintenance:
- High user activity periods: Service interruptions during peak usage amplify business impact. Schedule server restarts during established maintenance windows when user traffic reaches minimum levels and coordinate with business stakeholders to identify optimal timing.
- Critical business events: E-commerce platforms and transaction processing systems require special attention around peak sales periods. Avoid reboots during holiday seasons, promotional events or other high-revenue periods when system availability directly impacts business results.
These timing and operational considerations set the foundation for making informed reboot decisions. However, even with optimal timing, rebooting a server carries inherent risks if proper precautions aren’t taken. To minimize downtime and prevent complications, following a systematic pre-reboot checklist is essential.
Pre-reboot checklist to avoid downtime
Systematic preparation minimizes restart risks and ensures smooth recovery procedures. Following established checklists prevents common oversights that cause extended outages or data loss.
Before initiating any server restart, you’ll need to work through several critical checkpoints. These verification steps help ensure a seamless reboot process and reduce the risk of unexpected complications.
1. Quick checks before restarting
Start by reviewing your server’s current state to identify any potential issues that could complicate the restart process. Here are the essential checks you should perform:
- Verify current user sessions and active connections before initiating restart procedures. Check for logged-in administrators, active SSH sessions and remote desktop connections that need proper notification and graceful disconnection.
- Monitor running jobs, scheduled tasks and automated processes that might be interrupted by restart procedures. Use process monitoring commands to identify long-running operations that should complete before system shutdown.
- Assess current disk space and memory usage to ensure sufficient resources for normal startup procedures. Low disk space can prevent proper system initialization or cause boot failures that require emergency recovery procedures.
- Test backup systems and verify recent backup completion before proceeding with restart operations. Ensure that current data backups exist and restoration procedures are readily available if unexpected issues occur during reboot.
With these technical validations complete, your next step involves ensuring proper communication channels and alternative access methods are in place.Proper preparation extends beyond technical checks. You’ll also need to establish backup access methods and notify relevant stakeholders:
2. Access and communication prep
Before rebooting a server, establishing reliable communication channels and backup access methods is critical to prevent complete lockout situations. This preparation step ensures you can quickly respond to unexpected issues during the restart process and maintain control over your server infrastructure.
- Confirm alternative access methods including console access, out-of-band management interfaces or physical server access before initiating remote restarts. Network configuration changes during restart might prevent standard SSH or remote access methods.
- Notify relevant team members and stakeholders about planned restart windows and expected duration. Provide contact information and escalation procedures for emergency situations that might arise during restart operations.
- Document current system configuration and running services for reference during post-reboot verification procedures. This documentation helps identify missing services or configuration changes that occur during restart.
Successful restart completion requires systematic verification to ensure all services function properly and system performance returns to expected levels. Once you’ve taken these preparatory measures, understanding what to check after rebooting a server becomes the next essential step.
What to check after rebooting a server?
After a server restart, thorough verification ensures your system is functioning optimally without introducing new issues. A systematic post-reboot checklist helps you catch problems early, before they affect users or disrupt business operations.
1. Confirm critical services are running
The first priority after any server reboot is ensuring all essential services have started correctly. Begin by checking web server functionality and testing sample web page responses using curl commands or browsers to confirm that applications load properly. Next, verify database connectivity to ensure services accept connections from application servers and run simple queries without corruption warnings. Finally, validate mail server operations by sending test messages to confirm that routing, spam filtering and user authentication are working as expected.
With service functionality confirmed, the next crucial step involves examining system logs for any warning signs that might indicate underlying problems.
2. Review logs for errors or warnings
System logs provide valuable insights into what happened during the reboot process. You should examine boot logs for hardware errors, driver loading failures or service startup problems that might indicate underlying issues, paying special attention to messages that appeared after the restart. It is also important to check application error logs for new warnings compared to pre-reboot baselines. Additionally, monitor system resources like CPU utilization and memory usage trends to confirm that performance improvements occurred as expected without recurring problems.
Beyond internal checks, it’s essential to validate how your server performs from an external perspective and ensure users can access their services without interruption.
3. Validate performance and connectivity
External validation ensures your server is truly ready to serve users. Test website and application access from multiple locations to confirm that both internal network access and external internet connectivity function properly. You should also monitor traffic patterns and latency measurements to verify that network performance meets established baselines. Overall, comparing current system performance metrics with pre-reboot measurements will confirm that the restart achieved the intended improvements without creating new bottlenecks.
Understanding the distinction between targeted service restarts and full system reboots helps you optimize maintenance procedures and minimize unnecessary downtime in the future.
Final thoughts
Server rebooting serves as a powerful troubleshooting tool when applied strategically and with proper timing. However, success depends on accurate problem diagnosis rather than automatic restart reflexes whenever system issues arise.
To ensure effective outcomes, systematic evaluation of performance symptoms, operational timing and business impact is essential before initiating any restart procedure. This careful preparation, combined with thorough post-reboot verification, protects data integrity while minimizing service disruption to your users.
Beyond immediate troubleshooting, smart server restart practices balance quick problem resolution with long-term system stability goals. By implementing regular monitoring, preventive maintenance and documented procedures, you can maintain optimal server performance while reducing the need for emergency restarts.
So, are you ready to enhance your server management capabilities? Bluehost provides reliable hosting infrastructure with built-in monitoring tools and expert support to help you maintain optimal server performance. Our managed hosting solutions include proactive monitoring, automated backups and 24/7 technical assistance to minimize downtime and streamline server maintenance procedures. Take control of your server performance today and explore our hosting plans to experience hassle-free server management.
ЧАВО
Перезагрузка сервера означает выполнение полной перезагрузки его операционной системы и всех запущенных служб. Этот процесс останавливает все приложения, очищает системную память и запускает систему с нуля, чтобы обновить системные ресурсы и решить накопившиеся проблемы с производительностью.
Выбирайте перезагрузку сервера вместо перезапуска службы при работе с обновлениями ядра, общим снижением производительности системы, множественными сбоями служб или проблемами с драйверами оборудования. Полная перезагрузка необходима, когда проблемы затрагивают основные системные компоненты, которые нельзя обновить независимо с помощью перезапуска служб.
Да, перезагрузка сервера всегда вызывает временный простой, пока система выключается и перезапускается. Типичное время простоя при перезагрузке составляет от 2 до 10 минут в зависимости от оборудования сервера и процессов запуска. Планируйте перезагрузку в периоды низкой нагрузки, чтобы минимизировать влияние на бизнес.
Большинство перезагрузок серверов завершаются в течение 3–5 минут на современном оборудовании. Сложным системам с множеством служб или более медленному оборудованию может потребоваться 10–15 минут. Корпоративным системам с расширенными процедурами запуска для полной инициализации может понадобиться 15–30 минут.
Перезагрузка активирует обновления безопасности и системные патчи, требующие изменений на уровне ядра или модификаций основных систем. Многие обновления безопасности и системные исправления не вступают в силу до следующего цикла перезапуска, что делает перезагрузку необходимой для поддержания безопасности и функциональности системы.
Комментарии
Категории
Случайное
Yoast SEO: полный разбор стоимости,
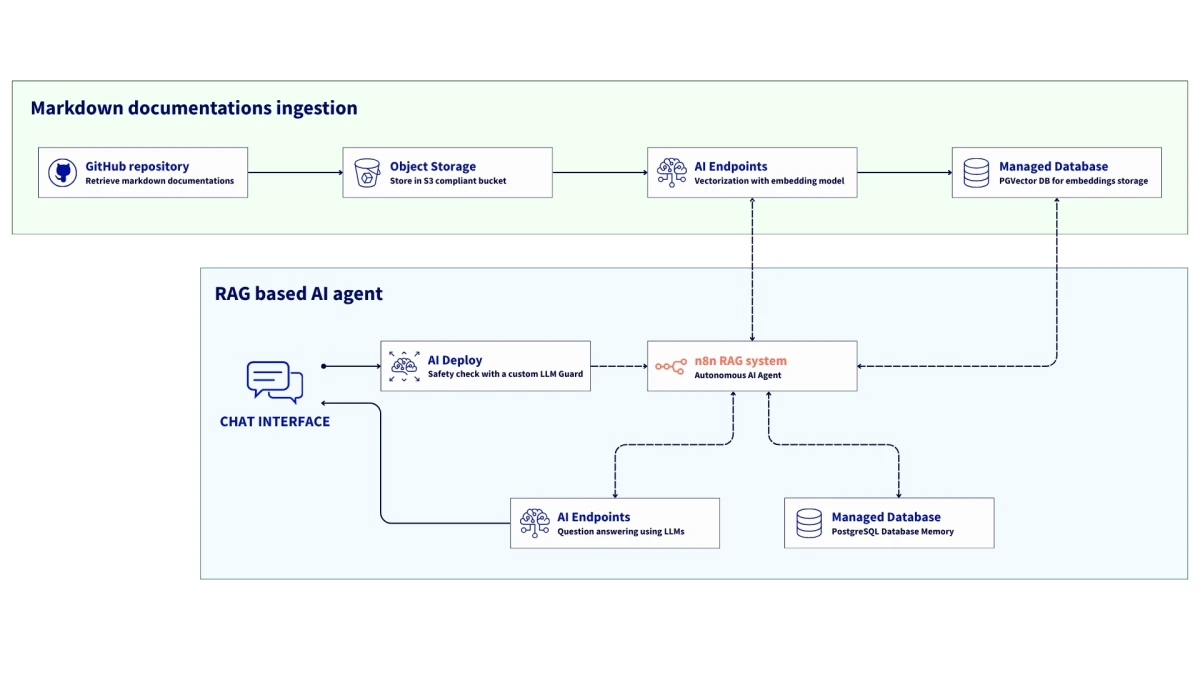
Как создать суверенного AI-агента с RAG
Кому действительно нужен AI-секретарь?
Перенос хостинга с GreenGeeks на
