Что, если n8n-воркфлоу, развернутый в суверенной среде, сэкономит ваше время и подарит спокойствие? От приема документов до генерации целевых ответов, n8n выступает в роли дирижера вашего RAG-конвейера, не жертвуя защитой данных.
В современных реалиях, где правят бал AI-агенты и помощники на базе знаний, подключение вашей внутренней документации к Большим Языковым Моделям (LLM) становится стратегическим преимуществом.
Как? Создавая Агентские RAG-системы, способные самостоятельно извлекать информацию, рассуждать и действовать на основе внешних знаний.
Для этого инженерам нужен способ связать конвейеры извлечения (RAG) с оркестрацией на основе инструментов.
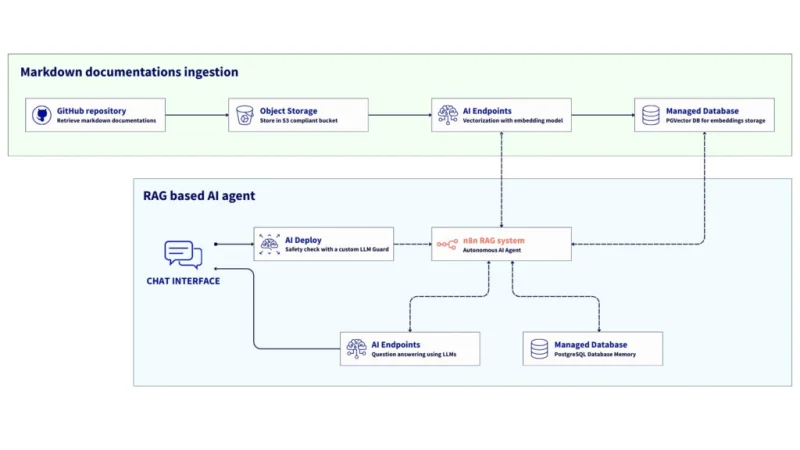
В этой статье представлена референтная архитектура для создания полностью автоматизированного RAG-конвейера под управлением n8n, в котором используются OVHcloud AI Endpoints и PostgreSQL с pgvector в качестве основных компонентов.
В результате получится система, которая автоматически загружает документацию в формате Markdown из Объектного Хранилища, создает эмбеддинги с помощью модели BGE-M3 от OVHcloud, доступной в AI Endpoints, и сохраняет их в Управляемой базе данных PostgreSQL с расширением pgvector.
Наконец, вы сможете создать AI-агента, который позволит вам общаться с LLM (GPT-OSS-120B в AI Endpoints). Этот агент, использующий реализованную выше по потоку RAG-систему, станет экспертом по продуктам OVHcloud.
Процесс можно улучшить, используя LLM-гард для защиты вопросов, отправляемых LLM, и настроив память чата для использования истории разговоров для повышения качества ответов.
Но при чем здесь n8n?
n8n, инструмент с открытым исходным кодом для автоматизации рабочих процессов, предлагает множество преимуществ и легко интегрируется с более чем 300 API, приложениями и сервисами:
- Открытый исходный код: n8n — это на 100% самостоятельное решение, что означает полный контроль над данными;
- Гибкость: сочетает low-code узлы и пользовательскую логику на JavaScript/Python;
- Готовность к AI: включает полезные интеграции для LangChain, OpenAI и возможности работы с эмбеддингами;
- Составной характер: позволяет за минуты устанавливать простые связи между данными, API и моделями;
- Суверенность по дизайну: соответствует требованиям конфиденциальности или регулируемых секторов.
Эта референтная архитектура служит образцом для создания суверенной, масштабируемой платформы для генерации с учетом извлеченной информации (RAG) с использованием n8n и решений OVHcloud Public Cloud.
Данная конфигурация показывает, как организовать прием данных, генерацию эмбеддингов и включить разговорный AI, комбинируя OVHcloud Object Storage, Управляемые базы данных PostgreSQL, AI Endpoints и AI Deploy.Результат? AI-среда, которая полностью интегрирована, защищает конфиденциальность и размещена исключительно на европейской инфраструктуре OVHcloud.
Обзор архитектуры n8n-воркфлоу для RAG
Рабочий процесс включает следующие шаги:
- Прием данных: документация в формате markdown извлекается из OVHcloud Object Storage (S3);
- Предварительная обработка: n8n очищает и нормализует текст, удаляя YAML front-matter и помехи кодирования;
- Векторизация: Каждый документ преобразуется в эмбеддинги с помощью модели BGE-M3, доступной через OVHcloud AI Endpoints;
- Сохранение: векторы и метаданные хранятся в Управляемой базе данных PostgreSQL от OVHcloud с использованием pgvector;
- Извлечение: когда пользователь отправляет запрос, n8n запускает LangChain Agent, который извлекает релевантные фрагменты из базы данных;
- Рассуждение и действия: Узел AI Agent объединяет логику LLM, память и использование инструментов для генерации контекстного ответа или запуска последующих действий (ответ в Slack, обновление в Notion, API-вызов и т.д.).
В этом руководстве все сервисы развертываются в рамках OVHcloud Public Cloud.
Предварительные требования
Перед началом убедитесь, что у вас есть:
- учетная запись OVHcloud Public Cloud
- Пользователь OpenStack со следующими ролями:
- Администратор
- AI-оператор
- Оператор объектного хранилища
- API-ключ для AI Endpoints
- Доступный ovhai CLI – установите ovhai CLI
- Доступ к Hugging Face – создайте учетную запись Hugging Face и сгенерируйте токен доступа
🚀 Теперь, когда у вас есть всё необходимое, можно приступать к созданию своего n8n-воркфлоу!
Руководство по архитектуре: агентский RAG-воркфлоу на n8n
Всё готово для настройки и развертывания вашего n8n-воркфлоу.
⚙️ Имейте в виду, что следующие шаги могут быть выполнены с использованием OVHcloud API!
Шаг 1 – Создание конвейера приема данных для RAG
Этот первый шаг предполагает создание основы всего RAG-воркфлоу путем подготовки необходимых элементов:
- развертывание n8n
- создание бакета в Объектном Хранилище
- создание базы данных PostgreSQL
- и другое
Не забудьте настроить соответствующие учетные данные в n8n, чтобы различные элементы могли подключаться и функционировать.
1. Разверните n8n на VPS от OVHcloud
OVHcloud предлагает VPS-решения, совместимые с n8n. Получите готовый к использованию виртуальный сервер с предустановленным n8n и начните создавать рабочие процессы автоматизации без ручной настройки. Планы варьируются от 6 vCores / 12 ГБ ОЗУ до 24 vCores / 96 ГБ ОЗУ, что позволяет выбрать мощность, соответствующую вашей рабочей нагрузке.
Как настроить n8n на VPS?
Настройка n8n на VPS от OVHcloud обычно включает:
- Выбор и активацию вашего тарифного плана VPS от OVHcloud;
- Подключение к серверу по SSH и выполнение начальной настройки сервера, включая обновление ОС;
- Установку n8n, обычно с помощью Docker (рекомендуется для простоты управления и обновлений) или npm, следуя этому руководству;
- Настройку n8n с доменным именем, SSL-сертификатом для HTTPS и всеми необходимыми переменными окружения для баз данных или настроек.
Хотя OVHcloud предоставляет надежную VPS-платформу, подробные руководства по установке n8n можно найти в официальной документации n8n.
После завершения настройки вы можете сконфигурировать базу данных и бакет в Объектном Хранилище.
2. Создайте бакет в Объектном Хранилище
Сначала необходимо настроить источник данных. Здесь вы можете хранить всю свою документацию в совместимом с S3 бакете Объектного Хранилища.
Предполагается, что все файлы документации имеют формат Markdown.
Из Панели управления OVHcloud создайте новый контейнер Object Storage с решением S3-совместимого API; следуйте этому руководству.
Когда бакет будет готов, добавьте в него вашу документацию в формате Markdown.

Примечание: В этом руководстве мы используем различную документацию по продуктам OVHcloud, доступную в открытом доступе в репозитории GitHub, который поддерживается участниками OVHcloud.
Перейдите по этой ссылке для доступа к репозиторию.
Как это сделать? Извлеките все файлы guide.en-gb.md из репозитория GitHub и переименуйте каждый так, чтобы он соответствовал своей родительской папке.
Пример: документация об установке CLI ovhai docs/pages/public_cloud/ai_machine_learning/cli_10_howto_install_cli/guide.en-gb.md сохраняется в бакете ovhcloud-products-documentation-md как cli_10_howto_install_cli.md
В итоге у вас должен получиться общий вид, похожий на этот:

Сохраните следующие элементы и создайте новые учетные данные в n8n с именем OVHcloud S3 gra credentials:
- S3 Endpoint:
https://s3.gra.io.cloud.ovh.net/ - Регион:
gra - Access Key ID:
<your_object_storage_user_access_key> - Secret Access Key:
<your_pbject_storage_user_secret_key>

Затем создайте новый узел n8n, выбрав S3, а затем Get Multiple Files (Получить несколько файлов).
Настройте этот узел следующим образом:

Подключите этот узел к предыдущему, прежде чем переходить к следующему шагу.

После завершения первого этапа можно переходить к настройке векторной базы данных.
3. Настройте PostgreSQL Managed DB (pgvector)
На этом шаге вы можете настроить векторную базу данных, которая позволит хранить эмбеддинги, сгенерированные из ваших документов.
Как? Используя управляемые базы данных OVHcloud, расширение pgvector для PostgreSQL. Перейдите в Панель управления OVHcloud и выполните следующие шаги.
1. Перейдите в раздел Базы данных и аналитика > Базы данных
2. Создайте новую базу данных и выберите PostgreSQL и расположение дата-центра

3. Выберите тариф Production (Производственный) и Тип инстанса

4. Сбросьте пароль пользователя и сохраните его

5. Добавьте IP-адрес вашего инстанса n8n в белый список следующим образом

6. Запишите следующие параметры

Запишите эту информацию и создайте новые учетные данные в n8n с именем OVHcloud PGvector credentials:
- Хост:
<db_hostname> - База данных: defaultdb
- Пользователь:
avnadmin - Пароль:
<db_password> - Порт: 20184
При необходимости рассмотрите возможность включения кнопки Ignore SSL Issues (Insecure) (Игнорировать проблемы SSL (Небезопасно)) и установите значение Maximum Number of Connections (Максимальное количество соединений) равным 1000.

✅ Теперь вы подключены к базе данных! Но что насчет расширения PGvector?
Добавьте узел PosgreSQL в ваш рабочий процесс n8n Execute a SQL query (Выполнить SQL-запрос), и создайте расширение с помощью SQL-запроса, который должен выглядеть так:
-- при необходимости удалите таблицу
DROP TABLE IF EXISTS md_embeddings;
-- активируйте pgvector
CREATE EXTENSION IF NOT EXISTS vector;
-- создайте таблицу
CREATE TABLE md_embeddings (
id SERIAL PRIMARY KEY,
text TEXT,
embedding vector(1024),
metadata JSONB
);У вас должен получиться такой узел n8n:

Наконец, вы можете создать новую таблицу с именем md_embeddings с помощью этого узла. Создайте узел Stop and Error (Остановить и вывести ошибку) если возникнут ошибки при создании таблицы.

Готово! Ваша векторная БД подготовлена и готова к приему данных! Помните, что для конвейера загрузки данных RAG вам все еще нужна модель эмбеддингов.
4. Доступ к OVHcloud AI Endpoints
OVHcloud AI Endpoints — это управляемый сервис, предоставляющий готовые к использованию API для моделей ИИ, включая LLM, CodeLLM, модели эмбеддингов, преобразования речи в текст и модели работы с изображениями расположенные в европейской инфраструктуре OVHcloud.
Для векторизации различных документов в формате Markdown необходимо выбрать модель эмбеддингов: BGE-M3.
Обычно ваш ключ API AI Endpoints уже должен быть создан. Если нет, перейдите в меню AI Endpoints в Панели управления OVHcloud, чтобы сгенерировать новый ключ API.

После этого вы можете создать новые учетные данные OpenAI в вашем n8n.
Зачем нужны учетные данные OpenAI? Потому что API AI Endpoints полностью совместим с OpenAI, что упрощает интеграцию и обеспечивает суверенитет ваших данных.
Как? Благодаря единой конечной точке https://oai.endpoints.kepler.ai.cloud.ovh.net/v1, вы можете запрашивать различные модели AI Endpoints.

Это означает, что вы можете создать новый узел n8n, выбрав Postgres PGVector Store и Add documents to Vector Store (Добавить документы в векторное хранилище).
Настройте этот узел, как показано ниже:

Затем настройте Data Loader (Загрузчик данных) с пользовательским разделением текста и типом JSON.

Для разделителя текста доступны следующие варианты:

Чтобы завершить, выберите модель эмбеддингов BGE-M3 из списка моделей и установите значение Dimensions (Размерность) на 1024.

Теперь у вас есть всё необходимое для построения пайплайна обработки данных.
5. Настройка цикла пайплайна обработки
Чтобы использовать полностью автоматизированный пайплайн для приёма и векторизации документов, необходимо интегрировать несколько специфичных узлов, в основном:
Loop Over Items, который загружает каждый файл Markdown по одному, чтобы его можно было векторизовать;Code in JavaScript, который подсчитывает количество обработанных файлов, что впоследствии определяет количество запросов к модели эмбеддингов;- Условие
If, позволяющее проверять, когда достигнуто 400 запросов; - Узел
Wait, который делает паузу после каждых 400 запросов, чтобы избежать ограничения по частоте (rate limit); - Блок S3
Download a fileдля загрузки каждого файла Markdown; - Ещё один
Code in JavaScriptдля извлечения и обработки текста из файлов Markdown путём очистки и удаления специальных символов перед отправкой в модель эмбеддингов; - Узел PostgreSQL для
Execute a SQLзапроса, чтобы проверить, что таблица содержит векторы после завершения процесса (цикла).
5.1. Создание цикла для обработки каждого файла документации
Начните с создания узла Loop Over Items для обработки всех файлов Markdown по одному. Установите batch size (размер пакета) в этом цикле на 1.

Добавьте оператор Loop сразу после узла S3 Get Many Files, как показано ниже:

Пора реализовать содержимое цикла!
5.2. Подсчёт количества файлов с помощью фрагмента кода
Затем выберите узел Code in JavaScript из списка, чтобы отслеживать, сколько файлов было обработано. Установите Mode (Режим) на "Run Once for Each Item" и Language (Язык) кода на "JavaScript", затем добавьте следующий фрагмент кода в предназначенный для него блок.
// простой счетчик для каждого элемента
const counter = $runIndex + 1;
return {
counter
};
Убедитесь, что этот фрагмент кода включён в цикл.

Теперь вы можете начать добавлять часть с if в цикл.
5.3. Добавление условия, применяющего правило каждые 400 запросов
Здесь необходимо создать узел If и добавить следующее условие, которое вы зададите как выражение.
{{ (Number($json["counter"]) % 400) === 0 }}
Добавьте его сразу после подсчёта файлов:

Если это условие is true (истинно), активируйте узел Wait.
5.4. Вставка паузы после каждого набора из 400 запросов
Затем вставьте узел Wait, чтобы сделать паузу на несколько секунд перед возобновлением. Вы можете выбрать вариант Resume "After Time Interval" (Возобновить после интервала времени) и установить Wait Amount (Время ожидания) на "60:00" секунд.

Свяжите его с условием If, когда оно True (Истинно).

Далее можно приступить к загрузке файла Markdown и его обработке.
5.5. Запуск загрузки документации
Для этого создайте новый узел S3 Download a file и настройте его, используя это выражение для File Key (Ключ файла):
{{ $('Process each documentation file').item.json.Key }}
Хотите его подключить? Это просто: свяжите его с выходом узлов Wait и If, когда оператор 'if' возвращает False; это позволит обрабатывать файл только в том случае, если лимит запросов не превышен.

Вы почти у цели! Теперь необходимо извлечь и обработать текст из файлов Markdown — очистить и удалить любые специальные символы перед отправкой в модель эмбеддингов.
5.6 Очистка текстового содержимого Markdown
Затем создайте ещё один узел Code in JavaScript для обработки текста из файлов Markdown:
// извлечение бинарного содержимого
const binary = $input.item.binary.data;
// декодирование в чистый текст UTF-8
let text = Buffer.from(binary.data, 'base64').toString('utf8');
// очистка - удаление непечатаемых символов
text = text
.replace(/[^x09x0Ax0Dx20-x7EÀ-ÿ€£¥•–—‘’“”«»©®™°±§¶÷×]/g, ' ')
.replace(/s{2,}/g, ' ')
.trim();
// проверка длины
if (text.length > 14000) {
text = text.slice(0, 14000);
}
return [{
text,
fileName: binary.fileName,
mimeType: binary.mimeType
}];Выберите Mode (Режим) "Run Once for Each Item" и поместите приведённый выше код в предназначенный для JavaScript блок.

В завершение убедитесь, что выходной текст был отправлен в систему векторизации документов, которая была настроена в Шаге 3 – Настройка управляемой БД PostgreSQL (pgvector).

Как мне подтвердить, что таблица содержит все элементы после векторизации?
5.7. Двойная проверка наличия документов в таблице
Чтобы убедиться, что ваша RAG-система работает, проверьте, что ваша векторная база данных содержит различные векторы; используйте узел PostgreSQL с Execute a SQL query в вашем рабочем процессе n8n.
Затем выполните следующий запрос:
-- подсчитать количество элементов
SELECT COUNT(*) FROM md_embeddings;
Затем свяжите этот элемент с разделом Готово вашего Цикла, чтобы элементы подсчитывались после завершения процесса.

Поздравляем! Теперь вы можете запустить рабочий процесс для начала загрузки документов.
Нажмите кнопку Выполнить рабочий процесс и дождитесь завершения процесса векторизации.

Помните, все должно быть зеленым по завершении ✅.
Шаг 2 – RAG-чатбот
После завершения этапов загрузки данных и векторизации вы можете приступить к реализации вашего AI-агента.
Это предполагает создание ИИ-агента на основе RAG, просто начав чат с LLM.
1. Настройте окно чата для начала разговора
Сначала настройте вашего AI-агента на основе RAG-системы и добавьте новый узел в тот же рабочий процесс n8n: Chat Trigger.

Этот узел позволит вам напрямую взаимодействовать с вашим AI-агентом! Но перед этим нужно убедиться, что ваше сообщение безопасно.
Этот узел позволит вам напрямую взаимодействовать с вашим AI-агентом! Но перед этим нужно убедиться, что ваше сообщение безопасно.
2. Настройте ваш LLM Guard с помощью AI Deploy
Чтобы проверить, безопасно ли сообщение, используйте LLM Guard.
Что такое LLM Guard? Это слой безопасности и контроля, который располагается между пользователями и LLM или между LLM и внешним подключением. Его основная цель — фильтровать, отслеживать и применять правила к тому, что поступает в модель или выходит из нее 🔐.
Вы можете использовать AI Deploy от OVHcloud для развертывания желаемого LLM guard. С помощью одной командной строки это AI-решение позволяет развернуть модель Hugging Face, используя Docker-контейнеры vLLM.
Для получения более подробной информации обратитесь к этому блогу.
Для рассматриваемого в этой статье варианта использования вы можете применить модель с открытым исходным кодом meta-llama/Llama-Guard-3-8B, доступную на Hugging Face.
2.1 Создайте Bearer-токен для запросов к вашему пользовательскому AI Deploy endpoint
Создайте токен для доступа к вашему приложению AI Deploy после его развертывания.
ovhai token create --role operator ai_deploy_token=my_operator_tokenВозвращается следующий вывод:
Id: 47292486-fb98-4a5b-8451-600895597a2b
Created At: 20-10-25 8:53:05
Updated At: 20-10-25 8:53:05
Spec:
Name: ai_deploy_token=my_operator_token
Role: AiTrainingOperator
Label Selector:
Status:
Value: XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
Version: 1
Теперь вы можете сохранить и экспортировать ваш токен доступа, чтобы добавить его в качестве новых учетных данных в n8n.
export MY_OVHAI_ACCESS_TOKEN=XXXXXXXXXXXXXXXXXXXXXXXXXXXXXX2.1 Запустите модель Llama Guard 3 с помощью AI Deploy
Используя CLI ovhai, выполните следующую команду для запуска сервера вывода vLLM.
ovhai app run
--name vllm-llama-guard3
--default-http-port 8000
--gpu 1
--flavor l40s-1-gpu
--label ai_deploy_token=my_operator_token
--env OUTLINES_CACHE_DIR=/tmp/.outlines
--env HF_TOKEN=$MY_HF_TOKEN
--env HF_HOME=/hub
--env HF_DATASETS_TRUST_REMOTE_CODE=1
--env HF_HUB_ENABLE_HF_TRANSFER=0
--volume standalone:/workspace:RW
--volume standalone:/hub:RW
vllm/vllm-openai:v0.10.1.1
-- bash -c python3 -m vllm.entrypoints.openai.api_server
--model meta-llama/Llama-Guard-3-8B
--tensor-parallel-size 1
--dtype bfloat16Полное пояснение команды:
ovhai app run
Это основная команда для запуска приложения с использованием платформы OVHcloud AI Deploy.
--name vllm-llama-guard3
Задает пользовательское имя для задачи. Например, vllm-llama-guard3.
--default-http-port 8000
Открывает порт 8000 в качестве HTTP endpoint по умолчанию. Сервер vLLM обычно работает на порту 8000.
--gpu1--flavor l40s-1-gpu
Выделяет 1 GPU L40S для приложения. Вы можете изменить тип и количество GPU в зависимости от модели, которую необходимо развернуть.
--volume standalone:/workspace:RW--volume standalone:/hub:RW
Подключает два тома постоянного хранения: /workspace, который является основной рабочей директорией, и /hub для хранения файлов моделей Hugging Face.
--env OUTLINES_CACHE_DIR=/tmp/.outlines--env HF_TOKEN=$MY_HF_TOKEN--env HF_HOME=/hub--env HF_DATASETS_TRUST_REMOTE_CODE=1--env HF_HUB_ENABLE_HF_TRANSFER=0
Это переменные окружения Hugging Face, которые необходимо установить. Пожалуйста, экспортируйте ваш токен доступа Hugging Face как переменную окружения перед запуском приложения: export MY_HF_TOKEN=***********
vllm/vllm-openai:v0.10.1.1
Используйте Docker-образ v (предварительно настроенный сервер OpenAI API на vLLM).llm/vllm-openai
-- bash -c python3 -m vllm.entrypoints.openai.api_server
--model meta-llama/Llama-Guard-3-8B
--tensor-parallel-size 1
--dtype bfloat16
Наконец, запустите bash-оболочку внутри контейнера и выполните команду Python для запуска сервера API vLLM.
2.2 Проверка, чтобы убедиться, что ваше приложение AI Deploy работает
Замените <app_id> на ваш.
ovhai app get <app_id>Вы должны получить:
История:
ДАТА СОСТОЯНИЕ
20-1O-25 09:58:00 В ОЧЕРЕДИ
20-10-25 09:58:01 ИНИЦИАЛИЗАЦИЯ
04-04-25 09:58:07 ОЖИДАНИЕ
04-04-25 10:03:10 РАБОТАЕТ
Информация:
Сообщение: Приложение запущено
2.3 Создание новых учетных данных n8n с URL приложения AI Deploy и токеном доступа Bearer
Сначала, используя ваш <app_id>, получите URL вашего приложения AI Deploy.
ovhai app get <app_id> -o json | jq '.status.url' -rЗатем создайте новые учетные данные OpenAI в вашем рабочем процессе n8n, используя ваш URL AI Deploy и токен Bearer в качестве API-ключа.

Не забудьте заменить 6e10e6a5-2862-4c82-8c08-26c458ca12c7 на ваш <app_id>.
2.4 Создание узла LLM Guard в рабочем процессе n8n
Создайте новый узел OpenAI для Отправки сообщения модели и выберите новые учетные данные AI Deploy для использования LLM Guard.
Затем создайте промпт следующим образом:
{{ $('Chat with the OVHcloud product expert').item.json.chatInput }}
Затем используйте узел If (Если), чтобы определить, является ли сценарий safe (безопасным) или unsafe (небезопасным):

Если сообщение unsafe (небезопасно), немедленно отправьте сообщение об ошибке, чтобы остановить рабочий процесс.

Но если сообщение safe (безопасно), вы можете отправить запрос к ИИ-агенту без проблем 🔐.
3. Настройка ИИ-агента
Узел ИИ-агент в n8n действует как интеллектуальный оркестрационный слой, который объединяет языковые модели (LLM), память и внешние инструменты в автоматизированном рабочем процессе.
Он позволяет вам:
- Подключать большую языковую модель (LLM) с использованием API (например, модели из AI Endpoints);
- Использовать инструменты, такие как HTTP-запросы, базы данных или RAG-извлекатели, чтобы агент мог выполнять действия или получать актуальную информацию;
- Поддерживать историю диалога через базы данных PostgreSQL;
- Интегрироваться напрямую с чат-платформами (например, Slack, Teams) для создания интерактивных ассистентов (опционально).
Проще говоря, n8n становится фреймворком для агентной автоматизации, позволяя LLM не только давать ответы, но и мыслить, выбирать и выполнять действия.
Обратите внимание, что вы можете изменить и настроить этот узел n8n AI Agent (ИИ-агент) в соответствии с вашими задачами, используя такие функции, как вызов функций или структурированный вывод. Это базовая конфигурация для данного случая использования. Вы можете пойти еще дальше с различными агентами.
🧑💻 Как реализовать этот RAG?
Сначала создайте узел AI Agent (ИИ-агент) в n8n следующим образом:

Затем требуется выполнить серию шагов, первый из которых — создание промптов.
3.1 Создание промптов
В узле ИИ-агента в вашем рабочем процессе n8n отредактируйте промпты пользователя и системы.
Начните с создания промпта, который также является сообщением пользователя:
{{ $('Chat with the OVHcloud product expert').item.json.chatInput }}Затем создайте Системное сообщение, как показано ниже:
У вас есть доступ к инструменту-извлекателю, подключенному к базе знаний.
Прежде чем отвечать, всегда ищите соответствующие документы с помощью инструмента-извлекателя.
Используйте извлеченный контекст для точного ответа.
Если соответствующие документы не найдены, сообщите, что у вас нет информации об этом.Вы должны получить следующую конфигурацию:

🤔 Итак, теперь для работы этого узла нужна языковая модель (LLM)!
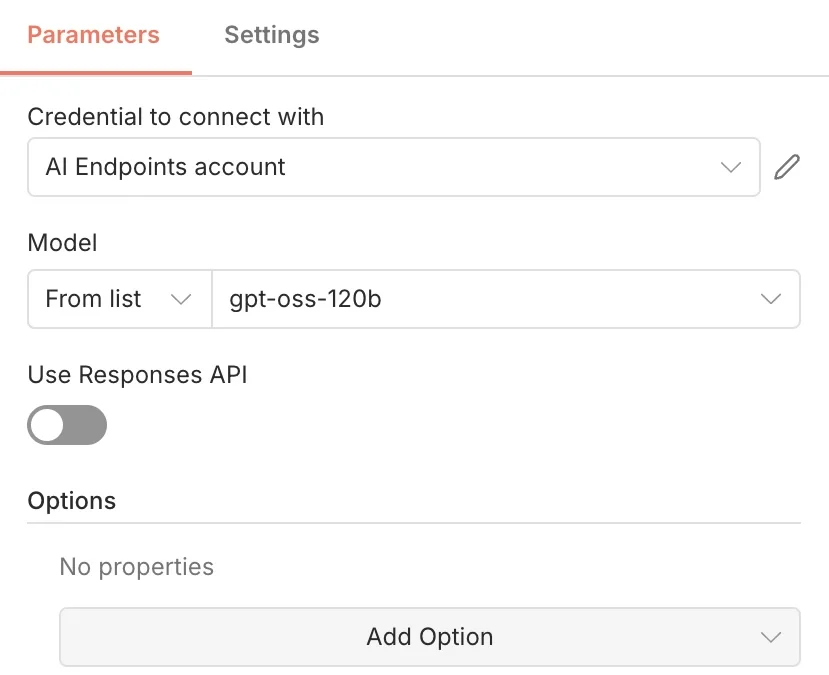
3.2 Выбор LLM с использованием API AI Endpoints
Сначала добавьте узел Модель чата OpenAI, а затем установите его как Chat Model (Модель чата) для вашего агента.

Затем выберите одну из OVHcloud AI Endpoints из предоставленного списка, поскольку они совместимы с OpenAI API.
✅ Как? Используя правильный API https://oai.endpoints.kepler.ai.cloud.ovh.net/v1

Для этого случая использования была выбрана модель GPT OSS 120B. Также доступны другие модели, такие как Llama, Mistral и Qwen.
⚠️ ВНИМАНИЕ ⚠️
Если вы используете свежую версию n8n, вы, скорее всего, столкнетесь с проблемой
/responses(связанной с совместимостью OpenAI). Чтобы решить эту проблему, вам нужно отключить кнопкуUse Responses API(Использовать API Responses), и тогда всё будет работать корректно.
Теперь ваша LLM настроена для ответов на вопросы! Не забудьте, ей нужен доступ к базе знаний.
3.3 Подключение базы знаний к RAG-извлекателю
Как обычно, первый шаг — создать узел n8n под названием PGVector Vector Store node (Узел векторного хранилища PGVector) и ввести ваши учетные данные PGvector.

Затем свяжите этот элемент с разделом Tools (Инструменты) узла ИИ-агента.

Не забудьте подключить вашу базу данных PG vector, чтобы извлекатель имел доступ к ранее созданным эмбеддингам. Вот обзор того, что вы получите.

⏳Почти готово! Финальный шаг — добавить память базы данных.
3.4 Управление историей диалога с помощью памяти базы данных
Создание узла Database Memory в n8n (PostgreSQL) позволяет связать его с вашим AI-агентом, чтобы он мог хранить и извлекать историю прошлых разговоров. Это позволяет модели запоминать и использовать контекст из множественных взаимодействий.

Итак, свяжите эту базу данных PostgreSQL с разделом Memory вашего AI-агента.

Поздравляем! 🥳 Ваш n8n RAG workflow теперь завершён. Готовы его протестировать?
4. Получите максимум от вашего автоматизированного workflow
Хотите попробовать? Это просто!
Нажав оранжевую кнопку Open chat, вы можете задавать AI-агенту вопросы о продуктах OVHcloud, особенно в тех случаях, когда вам нужна техническая помощь.
Например, вы можете спросить LLM о лимитах запросов в OVHcloud AI Endpoints и получить информацию за считанные секунды.
Теперь вы можете построить свою собственную автономную RAG-систему, используя OVHcloud Public Cloud, которая подходит для широкого спектра приложений.
Что дальше?
Подводя итог, эта референсная архитектура представляет собой руководство по использованию n8n с OVHcloud AI Endpoints, AI Deploy, Object Storage и PostgreSQL + pgvector для создания полностью контролируемой, автономной RAG AI-системы.
Команды могут создавать масштабируемых AI-ассистентов, которые работают безопасно и независимо в их облачном окружении, оркестрируя процесс индексации, генерации эмбеддингов, векторного хранения, поиска, проверки безопасности LLM и логических рассуждений в рамках единого workflow.
Имея готовую базовую архитектуру, вы можете добавить больше функций для улучшения возможностей и отказоустойчивости вашей агентской RAG-системы:
- Веб-поиск
- Изображения с OCR
- Аудиофайлы, транскрибированные с помощью модели Whisper

Комментарии
Категории
Случайное
Yoast SEO: полный разбор стоимости,
Как создать суверенного AI-агента с RAG
Кому действительно нужен AI-секретарь?
Перенос хостинга с GreenGeeks на
