Половина «открытых» моделей, которые рекомендуют на Reddit, заставили бы глаз Ричарда Столмана дёргаться. Llama использует Community лицензию со строгими ограничениями, а Gemma поставляется с Условиями использования, которые вам обязательно стоит прочитать, прежде чем использовать её в чём-либо.
Сам термин стал бессмысленным из-за чрезмерного употребления, поэтому, прежде чем рекомендовать какое-либо ПО, давайте сначала проясним определение.
Вам на самом деле нужны модели с открытыми весами (open-weight). Веса — это загружаемые «мозги» ИИ. В то время как обучающие данные и методы могут оставаться коммерческой тайной, вы получаете важную часть: модель, которая работает полностью на подконтрольном вам оборудовании.
В чем разница между Open-Source, Open-Weights и Terms-Based ИИ?
«Открытость» в современном ИИ — это спектр, требующий осторожного подхода, чтобы избежать юридических ловушек.

Мы разделили три основные категории, определяющие текущую экосистему, чтобы прояснить, что именно вы загружаете.
| Категория | Определение | Типичные лицензии | Безопасность для коммерции |
| Open Source ИИ (строгое) | Соответствует определению Open Source Initiative (OSI); вы получаете веса, обучающие данные и «предпочтительную форму» для модификации модели. | OSI-Approved | Абсолютная; у вас есть полная свобода использовать, изучать, изменять и делиться. |
| Open-Weights | Вы можете загрузить и запустить «мозг» (веса) локально, но обучающие данные и «рецепт» часто остаются закрытыми. | Apache 2.0, MIT | Высокая; как правило, безопасно для коммерческих продуктов, дообучения и распространения. |
| Source-Available/Terms-Based | Веса доступны для загрузки, но конкретные юридические условия строго диктуют, как, где и кем они могут использоваться. | Llama Community, Gemma Terms | Ограниченная; часто включает пороги использования (например, >700M пользователей) и политики допустимого использования. |
Почему важно определение «открытости»?
Модели с открытыми весами вступили в более зрелую фазу примерно в середине 2025 года. «Открытость» всё больше означает не просто загружаемые веса, а то, какую часть системы вы можете проверить, воспроизвести и контролировать.
- Открытость — это спектр: В ИИ «открытость» — это не метка да/нет. Одни проекты открывают веса, другие — методы обучения, третьи — оценки. Чем больше частей системы вы можете проверить и воспроизвести, тем она по-настоящему открытее.
- Цель открытости — суверенитет: Настоящая ценность моделей с открытыми весами — контроль. Вы можете запускать их там, где находятся ваши данные, адаптировать их под свои рабочие процессы и продолжать работу, даже когда поставщики меняют цены или политики.
- Открытость означает проверяемость: Открытость не волшебным образом убирает смещения или галлюцинации, но она даёт вам возможность проводить аудит модели и применять собственные защитные механизмы.
💡Совет: Если вы не уверены, к какой категории относится выбранная вами модель, сделайте быструю проверку. Найдите карточку модели на Hugging Face, прокрутите до раздела с лицензией и прочтите её. Apache 2.0 — обычно самый безопасный выбор для коммерческого использования.
Как объём памяти GPU определяет, какие модели вы можете запустить?
Никто не выбирает «лучшую» модель на рынке. Люди выбирают модель, которая лучше всего вписывается в их VRAM, чтобы не было сбоев. Бенчмарки не имеют значения, если для модели требуется 48 ГБ памяти, а у вас RTX 4060.
Чтобы не тратить время на тестирование заведомо невозможных рекомендаций, вот три основных фактора, потребляющих память GPU во время инференса:
- Веса модели: Это ваша базовая стоимость. Модель с 8 миллиардами параметров в полной точности (FP16) занимает примерно 16 ГБ просто для загрузки — удвоение параметров удваивает память.
- Ключ-значение кэш (Key-Value Cache): Он растёт с каждым введённым словом. Каждый обработанный токен выделяет память для «внимания» (attention), а это значит, что модель, которая успешно загрузилась, всё ещё может «упасть» на середине длинного документа, если вы заполните весь контекст.
- Накладные расходы: Фреймворки и драйверы CUDA навсегда резервируют ещё от 0.5 до 1 ГБ. Это неизбежно, и эта память просто недоступна.
Однако, если вы хотите запускать модели с большим числом параметров, обратите внимание на квантизацию. Снижение точности весов с 16-бит до 4-бит может уменьшить занимаемый моделью объём памяти примерно на 75% практически без потери качества.
Отраслевой стандарт — Q4_K_M (формат GGUF) — сохраняет около 95% от исходной производительности для чатов и программирования, одновременно снижая требования к памяти.
Чего ожидать от разных конфигураций VRAM?
Объём вашей VRAM определяет ваш опыт: от быстрых простых чат-ботов до возможностей, близких к передовым. Эта краткая таблица реалистично показывает, что вы можете запустить.
| VRAM GPU | Комфортный размер модели (квантизированной) | Что ожидать |
| 8 ГБ | ~3B до 7B параметров | Быстрые ответы, базовая помощь в программировании и простой чат. |
| 12 ГБ | ~7B до 10B параметров | Сладкое пятно для «ежедневного водителя»; хорошие рассуждения, следование инструкциям. |
| 16 ГБ | ~14B до 20B параметров | Заметный скачок возможностей; лучшее генерирование кода и сложная логика. |
| 24 ГБ+ | ~27B до 32B параметров | Качество, близкое к передовому; более медленная генерация, но отлично подходит для RAG и длинных документов. |
🤓Заметка для гиков: Длина контекста может взорвать потребление памяти быстрее, чем вы ожидаете. Модель, которая отлично работает с контекстом в 4K, может «захлебнуться» на 32K. Так что не выставляйте максимальный контекст, пока не сделали расчёты.
10 лучших самохостимых AI-моделей, которые можно запустить дома
Мы группируем их по объёму VRAM, потому что это то, что на самом деле важно. Бенчмарки приходят и уходят, но объём памяти вашего GPU — физическая константа.
Лучшие самохостимые AI-модели для 12 ГБ VRAM
Для уровня 12 ГБ вам нужна эффективность. Вам нужны модели, которые выдают результат выше своего класса.

1. Ministral 3 8B
Выпущенная в декабре 2025 года, она сразу стала моделью, которую нужно превзойти в этом размере. Она имеет лицензию Apache 2.0, является мультимодальной (может обрабатывать изображения вместе с текстом) и оптимизирована для развертывания на edge-устройствах. Mistral обучала её параллельно с более крупными моделями, что заметно по качеству вывода.
✅Вердикт: Ministral — король эффективности; её уникальная склонность к более коротким и точным ответам делает её самой быстрой моделью общего назначения в этом классе.
2. Qwen3 8B
От Alibaba, эта модель поставляется с функцией, которую пока никто больше не реализовал: гибридные режимы мышления. Вы можете дать ей инструкцию обдумывать сложные проблемы шаг за шагом или отключить рассуждения для быстрых ответов. Она обладает контекстным окном в 128K токенов и стала первым семейством моделей, обученным специально для Model Context Protocol (MCP).
✅Вердикт: Наиболее универсальная доступная 8-миллиардная модель, специально оптимизированная для агентских рабочих процессов, где ИИ должен работать со сложными инструментами или внешними данными.
3. Llama 3.1 8B Instruct
Она остается стандартом экосистемы. Каждая платформа поддерживает её, и каждый учебник использует её в качестве примера. Однако обратите внимание на лицензию: сообщество Meta соглашение не является открытым исходным кодом, и применяются строгие условия использования.
✅Вердикт: Самый безопасный выбор для совместимости с учебниками и инструментами при условии, что вы прочитали Community License и подтвердили, что ваш вариант использования ей соответствует.
4. Qwen2.5-Coder 7B Instruct
Эта модель создана с одной единственной целью: писать код. Обученная специально на программистских задачах, она превосходит многие более крупные модели общего назначения в тестах на генерацию кода, при этом требуя меньше памяти.
✅Вердикт: Отраслевой стандарт для локального парного программирования; используйте её, если хотите получать предложения, подобные Copilot, не отправляя проприетарный код в облако.
Лучшие самостоятельно развертываемые модели ИИ для 16 ГБ видеопамяти (VRAM)
Переход на 16 ГБ позволяет запускать модели, которые предлагают подлинную точку перелома в рассуждениях. Эти модели не просто болтают; они решают проблемы.
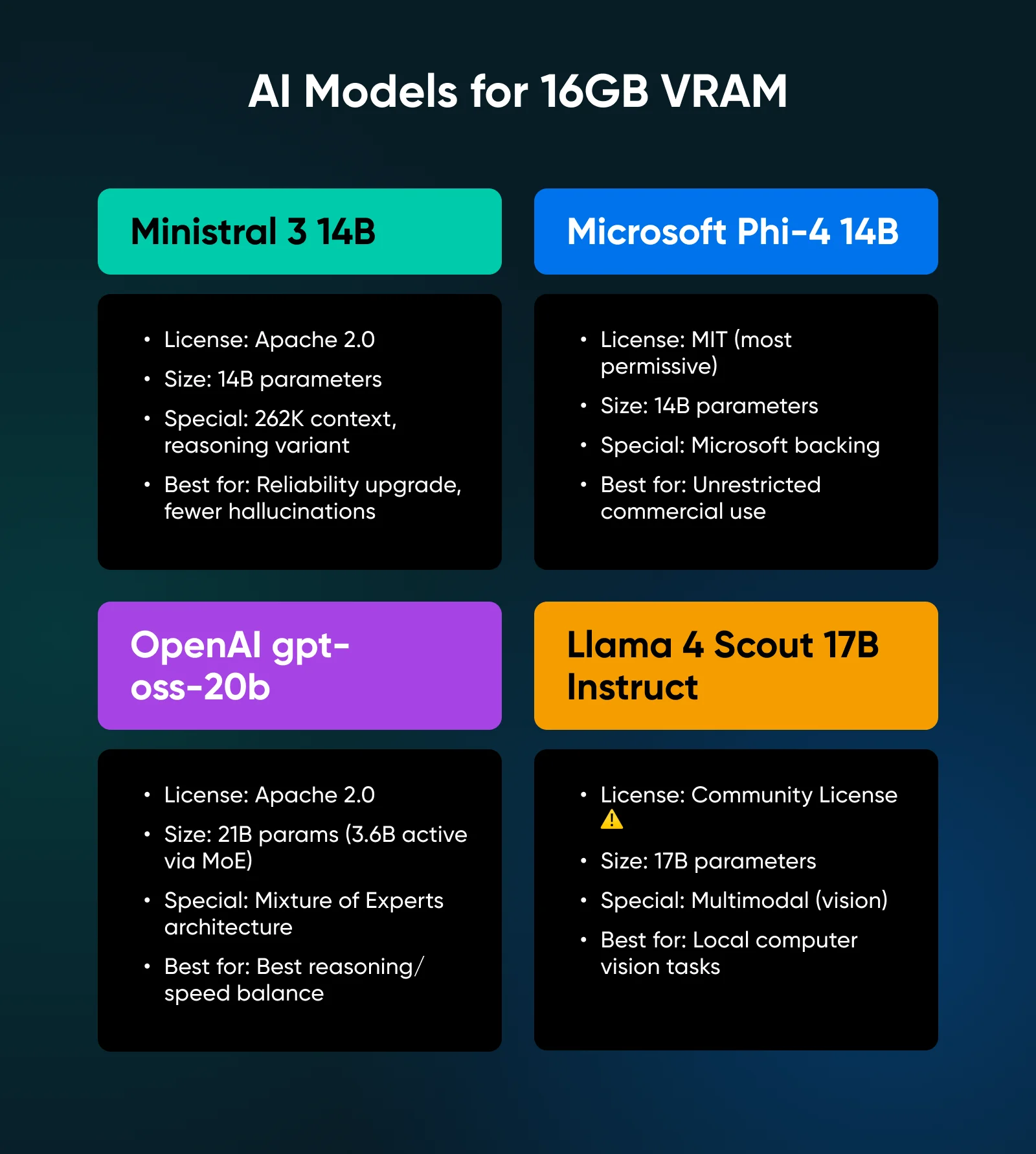
5. Ministral 3 14B
Она масштабирует архитектуру 8-миллиардной версии с тем же фокусом на эффективность. Предлагает окно контекста в 262 тыс. токенов и вариант для рассуждений, который достигает 85% на AIME 2025 (математическом бенчмарке конкурсного уровня).
✅Вердикт: Подлинное повышение надежности по сравнению с классом 8B; дополнительные затраты на видеопамять с лихвой окупаются за счет сокращения галлюцинаций и лучшего следования инструкциям.
6. Microsoft Phi-4 14B
Phi-4 поставляется под лицензией MIT, самой разрешительной из доступных. Никаких ограничений на использование; она демонстрирует высокую производительность на задачах, требующих рассуждений, и имеет поддержку Microsoft в долгосрочной перспективе.
✅Вердикт: Самый безопасный с юридической точки зрения выбор; выбирайте эту модель, если ваша главная забота — неограничивающая лицензия для коммерческого развертывания.
7. OpenAI gpt-oss-20b
После пяти лет закрытой разработки OpenAI выпустила эту модель с открытыми весами под лицензией Apache 2.0. Она использует архитектуру Mixture of Experts (MoE, Смесь экспертов), что означает, что у неё 21 миллиард параметров, но на каждый токен используется только 3,6 миллиарда активных параметров.
✅Вердикт: Техническое чудо, предлагающее лучший баланс возможностей рассуждения и скорости вывода в классе 16 ГБ.
8. Llama 4 Scout 17B Instruct
Последний выпуск модели Llama от Meta улучшает мультимодальные возможности, представленные в семействе Llama в версии 3, позволяя загружать изображения и задавать вопросы о них.
✅Вердикт: Лучший и наиболее отточенный вариант для локальных задач компьютерного зрения, позволяющий безопасно обрабатывать документы, чеки и скриншоты на собственном оборудовании.
Лучшие самостоятельно развертываемые модели ИИ для 24+ ГБ видеопамяти (VRAM)
Если у вас есть RTX 3090 или 4090, вы входите в уровень «Продвинутого пользователя», где можно запускать модели, приближающиеся по производительности к передовым.
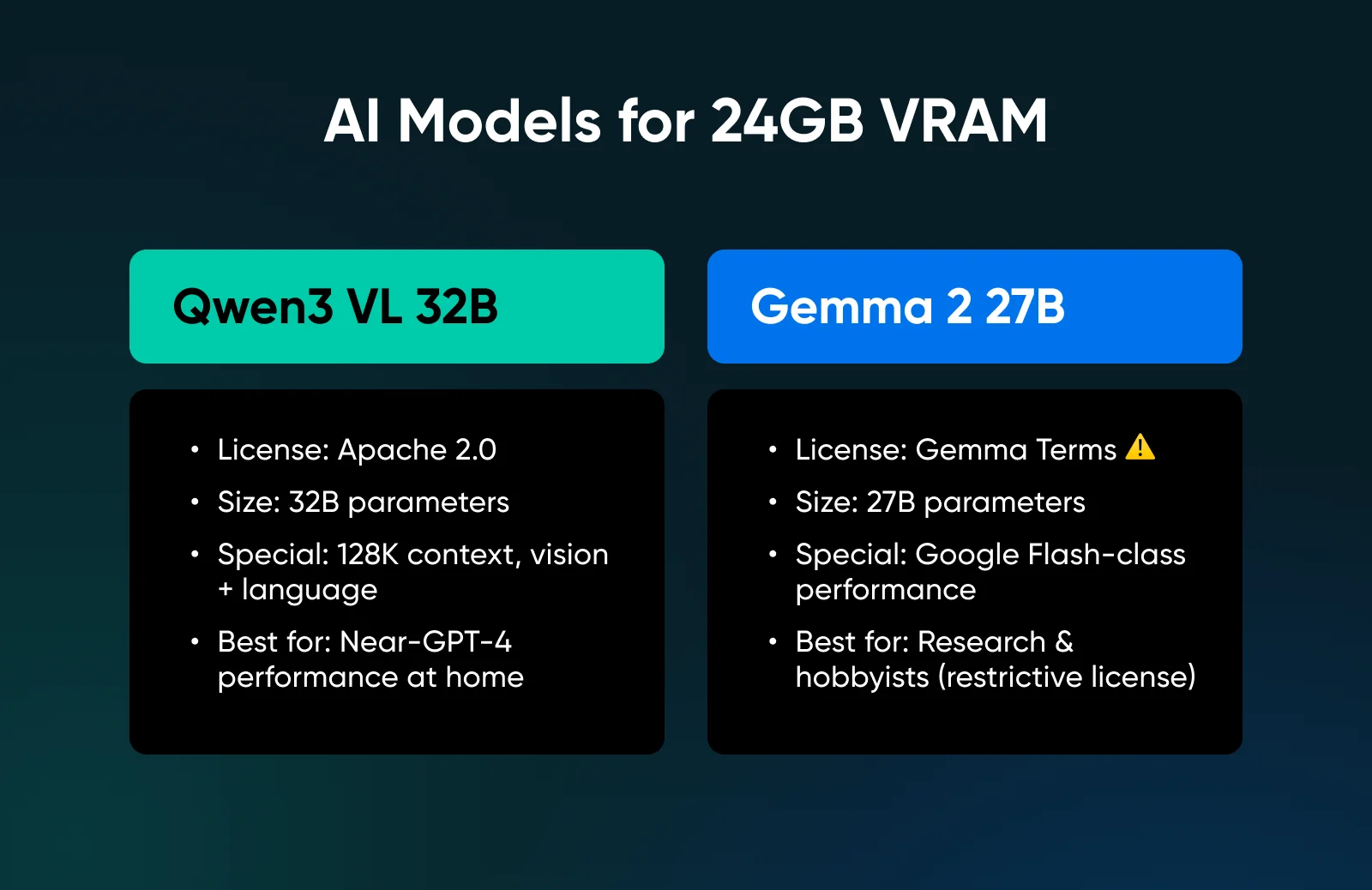
9. Qwen3 VL 32B
Эта модель нацелена именно на оптимальный уровень в 24 ГБ. Она предлагает почти все, что может понадобиться: лицензия Apache 2.0, контекстное окно в 128 тыс. токенов, модель для обработки зрения и языка с производительностью, соответствующей 72-миллиардной модели предыдущего поколения.
✅Вердикт: Абсолютный предел локального развертывания на одной видеокарте; это максимально близко к производительности уровня GPT-4, которую можно получить дома, не покупая сервер.
10. Gemma 2 27B
Google выпустил множество действительно сильных моделей Gemma, и эта наиболее близка к их онлайн-моделям Flash. Но обратите внимание, что эта модель не мультимодальна; однако она предлагает высокую производительность в работе с языком и рассуждениями.
✅Вердикт: Высокопроизводительная модель для исследователей и энтузиастов, хотя ограничительная лицензия делает её сложным выбором для коммерческих продуктов.
Бонус: Дистиллированные модели для рассуждений
Мы обязаны упомянуть модели, такие как DeepSeek R1 Distill. Они существуют в разных размерах и получены из более крупных родительских моделей, чтобы «думать» (тратить больше токенов на обработку) перед ответом.
Такие модели идеальны для конкретных математических или логических задач, где точность важнее задержки. Однако лицензирование полностью зависит от происхождения базовой модели: некоторые варианты получены из Qwen (Apache 2.0), в то время как другие — из Llama (Community License).
Всегда читайте карточку конкретной модели перед загрузкой, чтобы подтвердить свою правомерность.
Какие инструменты использовать для развертывания локальных моделей?
У вас есть оборудование и модель. Теперь, как её фактически запустить? Три инструмента доминируют в этой области для разных типов пользователей:
1. Ollama
Ollama широко считается стандартом для того, чтобы «запустить всё сегодня вечером». Он объединяет движок и управление моделями в один бинарный файл.
- Как это работает: Вы устанавливаете его, вводите ollama run llama3 или другое название модели из библиотеки, и через несколько секунд (в зависимости от размера модели и вашей видеопамяти) вы уже общаетесь.
- Ключевая особенность: Простота — она абстрагирует все детали квантования и пути к файлам, что делает её идеальной отправной точкой для новичков.
2. LM Studio
LM Studio предоставляет графический интерфейс для людей, которые предпочитают не жить в терминале. Вы можете визуализировать свою библиотеку моделей и управлять конфигурациями, не запоминая аргументы командной строки.
- Как это работает: Вы можете искать модели, загружать их, настраивать параметры квантования и запускать локальный API-сервер несколькими кликами.
- Ключевая особенность: Автоматическая разгрузка на аппаратное обеспечение; она удивительно хорошо справляется с интегрированными GPU. Если вы используете ноутбук со скромной дискретной видеокартой или на чипе Apple Silicon, LM Studio определяет ваше оборудование и автоматически распределяет модель между вашим CPU и GPU.
3. llama.cpp Server
Если вы хотите получить всю мощь открытого исходного кода без каких-либо «закрытых экосистем», вы можете запустить llama.cpp напрямую, используя его встроенный серверный режим. Это часто предпочитают опытные пользователи, потому что это исключает посредника.
- Как это работает: Вы загружаете бинарный файл llama-server, указываете ему на файл модели, и он запускает локальный веб-сервер — он легковесный и не имеет никаких ненужных зависимостей.
- Ключевая особенность: Нативная совместимость с OpenAI; простой командой вы мгновенно получаете API-эндпоинт, совместимый с OpenAI. Вы можете подключить его напрямую к приложениям для диктовки, расширениям VS Code или любому инструменту, созданному для ChatGPT, и это просто работает.
Когда следует переходить с локального оборудования на облачную инфраструктуру?

Локальное развертывание имеет пределы, и знание их экономит время и деньги.
Нагрузки от одного пользователя отлично работают локально, потому что это вы и ваш ноутбук против всего мира. Конфиденциальность абсолютна, задержка низкая, и после покупки оборудования ваши расходы равны нулю. Однако сценарии с несколькими пользователями очень быстро усложняются.
Два человека, запрашивающие одну и ту же модель, могут сработать, 10 человек — нет. Память GPU не умножается при добавлении пользователей. Параллельные запросы становятся в очередь, задержка взлетает, и все разочаровываются. Более того, длинный контекст плюс скорость создают невозможные компромиссы. Кэш KV масштабируется линейно с длиной контекста — обработка контекста в 100 тыс. токенов съедает видеопамять, которая могла бы использоваться для вывода.
Если вам нужно создать производственный сервис, набор инструментов меняется:
- vLLM: Обеспечивает высокопроизводительный вывод с помощью API, совместимых с OpenAI, промышленным уровнем обслуживания и оптимизациями, которые пропускают потребительские инструменты (например, PagedAttention).
- SGLang: Сосредоточен на структурированной генерации и ограниченных выводах, что крайне важно для приложений, которые должны выводить валидный JSON.
Эти инструменты рассчитаны на серверную инфраструктуру. Выделенный сервер с мощной GPU имеет больше смысла, чем попытки вывести вашу домашнюю сеть в интернет.
Вот быстрый способ определиться:
- Запускать локально: Если ваша цель — один пользователь, конфиденциальность и обучение.
- Арендовать инфраструктуру: Если ваша цель — сервис + одновременные подключения + надежность.
Начните строить свою собственную локальную лабораторию LLM уже сегодня
Вы запускаете модели дома, потому что хотите нулевую задержку, нулевые счета за API и полную приватность данных. Но ваша GPU становится физическим ограничителем. Поэтому, если вы попытаетесь впихнуть модель на 32B в 12GB видеопамяти, ваша система будет еле ползти или упадет.
Вместо этого используйте свой локальный компьютер для прототипирования, настройки промптов и проверки поведения модели.
Как только вам понадобится поделиться этой моделью с командой или гарантировать её работу, пока вы спите, прекратите бороться со своим железом и перенесите нагрузку на выделенный сервер, предназначенный для круглосуточной работы.
Вы всё равно получаете приватность локального решения, поскольку выделенные серверы логируют только часы использования, а не то, о чем вы общаетесь с размещенной моделью. И вы также избегаете первоначальных затрат на оборудование и его настройку.
Ваши следующие шаги:
- Проверьте свою видеопамять (VRAM): Откройте диспетчер задач или выполните nvidia-smi. Это число определяет список доступных вам моделей. Всё остальное второстепенно.
- Протестируйте модель на 7B параметров: Скачайте Ollama или LM Studio. Запустите Qwen3 или Ministral с 4-битной квантизацией, чтобы установить базовый уровень производительности.
- Определите свое узкое место: Если ваши контекстные окна упираются в лимиты памяти, или ваш вентилятор звучит как реактивный двигатель, оцените, не переросли ли вы локальный хостинг. Задачи с высокой параллельной нагрузкой принадлежат выделенным серверам, и, возможно, вам просто нужно сделать переход.

Максимальная мощность, безопасность и контроль
Выделенные серверы от DreamHost используют лучшее аппаратное и программное обеспечение, чтобы ваш сайт всегда был доступен и работал быстро.
Узнать большеЧасто задаваемые вопросы о локально размещенных AI-моделях
Могу ли я запустить LLM на 8GB видеопамяти (VRAM)?
Да. Qwen3 4B, Ministral 3B и другие модели менее 7B параметров работают комфортно. Используйте квантизацию Q4 и сохраняйте разумный размер контекстного окна. Производительность не будет соответствовать большим моделям, но функциональный локальный AI абсолютно возможен на начальных GPU.
Какую модель использовать для 12GB?
Ministral 8B — лидер по эффективности. А если вы занимаетесь сложной агентской работой или использованием инструментов, то Qwen3 8B справляется с Model Context Protocol (MCP) лучше, чем что-либо ещё в этом классе веса.
В чем разница между open-source и open-weights?
Open-source (строгое определение) означает, что у вас есть всё необходимое для воспроизведения модели: обучающие данные, код обучения, веса и документация.
Open-weights означает, что вы можете скачать и запустить модель, но обучающие данные и методы могут быть проприетарными.
Когда мне следует использовать облачный вывод вместо локального?
Когда модель не помещается в вашу видеопамять даже после квантизации — когда вам нужно обслуживать несколько одновременных пользователей, когда требования к контексту превышают возможности вашей GPU, или когда вам нужна надежность уровня сервиса с SLA и поддержкой.
Комментарии
Категории
Случайное
Деловая почта для бизнеса: полное

Bare Metal и Dedicated Server: в чем

Издатели получают прямой контроль:
Как писать тексты с ИИ: инструкция для