Создание конвейера данных в реальном времени раньше означало месяцы инфраструктурной работы. Вот как выглядит современный стек в 2026 году.
Ваша база данных выполняет свою работу. Она записывает каждую транзакцию, каждое событие, каждое изменение состояния, которое создает ваше приложение. Данные надежны, согласованны и безопасно хранятся.
Но база данных — это отправная точка, а не конечный пункт. Вопрос в том, что происходит после записи. Остаются ли эти данные в хранилище, отвечая на запросы приложения, в то время как инсайты, которые они могли бы дать, остаются заблокированными? Или они текут дальше, в реальном времени, к системам, созданным для того, чтобы извлекать из них смысл?
Раньше построение такого нисходящего конвейера было серьезным инфраструктурным проектом. Кластеры Kafka для развертывания и настройки, ансамбли ZooKeeper для управления, коннекторы для конфигурирования, приемники для подключения, реестр схем для эксплуатации. Команда могла потратить недели на возведение «лесов», прежде чем первое событие достигало аналитического движка.
В 2026 году архитектура конвейера не изменилась. Но изменилась операционная нагрузка. Управляемые услуги берут на себя обеспечение, репликацию, отказоустойчивость и обновления. То, что раньше требовало специальной платформенной команды, теперь занимает один день. Эта статья рассказывает, как выглядит полный конвейер данных в реальном времени, как соединяются его уровни и что нужно для его создания без построения инфраструктуры под ним.
Четыре уровня
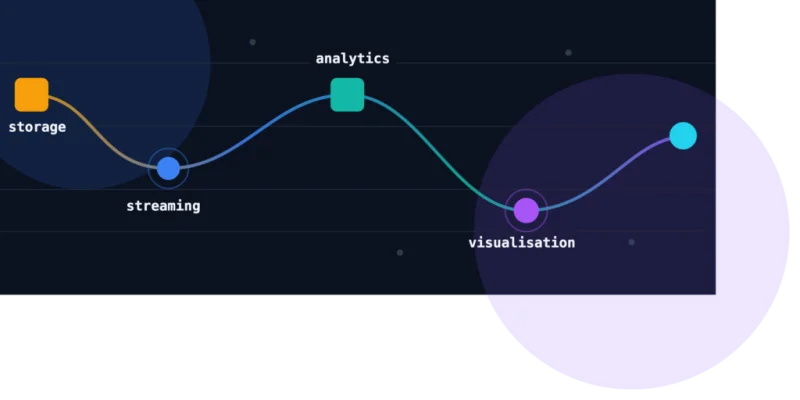
Современный конвейер данных в реальном времени состоит из четырех уровней. У каждого своя задача, и ни один из них не является опциональным, если вы хотите, чтобы данные непрерывно двигались от хранения к инсайтам.
Хранение
Место возникновения ваших данных. Реляционная база данных, такая как PostgreSQL, обрабатывает транзакции, обеспечивает согласованность и обслуживает ваше приложение. Это ваш источник правды. Каждая вставка, обновление и удаление записываются с точностью. Этот журнал записи также является отправной точкой для всего, что идет дальше.
Потоковая передача
Как данные движутся. Apache Kafka захватывает изменения из вашей базы данных в момент их возникновения и распределяет их downstream-потребителям в виде событий. Каждое изменение на уровне строки становится структурированным сообщением, на которое другие системы могут реагировать в реальном времени. Основной принцип дизайна Kafka — развязывание: производители записывают события, не зная, кто их будет потреблять, а потребители читают события, не затрагивая исходную систему. Это означает, что вы можете добавлять новые downstream-сценарии использования — новый аналитический движок, новую систему оповещения, новое хранилище данных — без изменения базы данных или приложения над ней.
Аналитика
Где данные превращаются в ответы. Два разных движка покрывают два основных сценария использования после хранения. ClickHouse обрабатывает OLAP-нагрузки: быстрые колоночные запросы, агрегации в реальном времени, анализ временных рядов и дашборды с миллионами строк в секунду. OpenSearch обрабатывает полнотекстовый поиск, аналитику логов и наблюдаемость: сложные запросы по неделям событийных данных, обнаружение аномалий, распределенную трассировку и правила оповещения по живым потокам событий. Оба движка спроектированы для чтения в масштабе, а не для транзакционной согласованности: это именно тот компромисс, который вам нужен после Kafka.
Визуализация
Как ответы доходят до людей. Grafana подключается как к ClickHouse, так и к OpenSearch, извлекая данные из живых источников для создания дашбордов, панелей оповещения и мониторов эксплуатации. Это уровень, который делает конвейер видимым для всей организации — для команды продукта, проверяющей внедрение функций, для команды безопасности, следящей за аномалиями, и для платформенной команды, отслеживающей состояние инфраструктуры.
Два пути через одну архитектуру
Топология одинакова независимо от вашего сценария использования: исходная база данных, Kafka как потоковый хребет, один или оба аналитических движка и Grafana сверху. То, как вы это строите, зависит от того, что вашей команде нужно в первую очередь.

Путь аналитики в реальном времени
PostgreSQL + Kafka + ClickHouse + Grafana — правильная отправная точка, когда основная потребность — быстрые и гибкие запросы. Аналитика продукта, бизнес-аналитика, отчетность по временным рядам, воронкообразный анализ, результаты A/B-тестов в реальном времени: все это требует ClickHouse. Он загружает данные напрямую из топиков Kafka, материализует представления, которые дашборды запрашивают за миллисекунды, и обрабатывает агрегации над сотнями миллионов строк без напряжения. SaaS-компания, которой нужно видеть использование функций по мере их появления, финтех, отслеживающий объемы транзакций по минутам, платформа электронной коммерции, выполняющая анализ живых запасов, — все они следуют этому же пути.
Путь поиска и наблюдаемости
PostgreSQL + Kafka + OpenSearch + Grafana — правильная отправная точка, когда основная потребность — полнотекстовый поиск, агрегация логов или системная наблюдаемость. OpenSearch индексирует события по мере их поступления, обеспечивая сложные поиски по месяцами структурированных и полуструктурированных данных с временем отклика менее секунды. Команда безопасности, коррелирующая события в распределенных сервисах, платформенная команда, централизующая логи десятков микросервисов, SRE-команда, строящая оповещения на основе живых потоков событий, — все они следуют этому пути.
Как движутся данные
Соединение между вашей базой данных и Kafka начинается с захвата изменений (change data capture, CDC). CDC — это механизм, который читает внутренний журнал записи вашей базы данных и превращает каждое изменение в поток структурированных событий.
В PostgreSQL это работает через логическую репликацию. Журнал упреждающей записи (WAL) фиксирует каждое изменение, сделанное в базе данных, на уровне строк. При включенной логической репликации коннектор может читать этот журнал и генерировать каждое изменение как структурированное событие с полным состоянием строки до и после. Kafka Connect — это уровень интеграции, который запускает эти коннекторы. Debezium, настроенный как коннектор-источник в Kafka Connect, читает WAL PostgreSQL и публикует каждое изменение в специальный топик Kafka. Оттуда коннекторы-приемники направляют события в ClickHouse, OpenSearch или оба.
Одно техническое достижение, которое стоит понять любому, кто строит на Kafka в 2026 году: Kafka 4.0 полностью удаляет ZooKeeper. ZooKeeper был внешним сервисом, на который Kafka полагался для управления метаданными кластера, выбора лидера и координации. Это была отдельная система, которую нужно было развертывать, настраивать, мониторить и обновлять вместе с брокерами Kafka. Kafka 4.0 заменяет его на KRaft, собственный протокол консенсуса на основе Raft. Метаданные кластера теперь управляются внутри самой Kafka. Результат — единая, автономная система с меньшим количеством компонентов, меньшим количеством режимов отказа и более быстрым восстановлением. Для тех, кто управлял кластером Kafka в модели ZooKeeper, это существенное упрощение. Для тех, кто использует Kafka как управляемую услугу, переход в основном незаметен: вы получаете более быстрый и отказоустойчивый кластер с одной операционной поверхностью меньше.
OpenSearch 3.0 также является значимым релизом для всех, кто строит конвейеры наблюдаемости. Обновление до Apache Lucene 10 обеспечивает до 60% снижения задержки поиска, причем наибольшие gains достигаются на векторном поиске, KNN и нейронном поиске. Индексирование Star-tree сокращает работу запросов для тяжелых агрегаций до 100 раз. А OpenSearch 3.0 добавляет нативную поддержку протокола MCP, что означает прямую интеграцию с AI-агентами и инструментарием на основе LLM. Для команд, строящих конвейеры наблюдаемости, которые питают AI-управляемое расследование инцидентов или рабочие процессы оповещения, это возможность, которая была недоступна еще двенадцать месяцев назад.
Почему управляемые услуги важны
Первое, что большинство команд недооценивает в этом стеке — это не начальная настройка, а постоянная операционная поверхность.
На Kafka более сложная работа начинается после запуска. Перебалансировка лидеров партиций при перезапуске брокера под нагрузкой. Восстановление кворума контроллера KRaft после отказа узла. Управление смещениями групп потребителей, когда коннектор-приемник отстает и вам нужно воспроизвести события без дублирования записей downstream. Настройка кучи JVM по мере роста пропускной способности. Политики перезапуска рабочих процессов коннекторов, которые не теряют события в полете. На OpenSearch добавьте решения по распределению шардов при масштабировании кластера, политики управления жизненным циклом индексов для контроля затрат на хранение по мере роста объема событий и настройку JVM для узлов ML, обеспечивающих векторный и нейронный поиск. На ClickHouse настройки Merge Tree и стратегия партиционирования важны с первого дня: неправильные решения на раннем этапе означают переписывание схем таблиц под нагрузкой.
Управляемые сервисы поглощают эту операционную поверхность. Поэтапные обновления выполняются без простоев, так как сервис управляет миграцией лидера перед выводом узла из сети. Коннекторы отслеживаются и перезапускаются автоматически. Обработка отказов осуществляется на уровне инфраструктуры между зонами доступности. Политики жизненного цикла индексов настраиваются через консоль, а не через ручное применение конфигурационных файлов. Инженеры по аналитике уже тратят до 40 процентов своего времени на обслуживание инфраструктуры, а не на получение инсайтов. Модель управляемых сервисов переносит эту сложность на уровень, который вам не нужно контролировать.
Для команд в Европе существует второе измерение. Развертывания гиперскейлеров в регионах ЕС работают на инфраструктуре, регулируемой законодательством США, что означает, что правовая основа доступа к вашим данным и условий такого доступа не является однозначной. Работа на OVHcloud означает, что инфраструктура европейская, операционный контроль европейский, а юрисдикция, регулирующая доступ к данным, однозначна. Для команд в регулируемых отраслях или для любой команды, которая сталкивается с вопросами соответствия GDPR от клиентов или аудиторов, это является существенным отличием от облачного региона, который просто находится в Европе.
Ценообразование — третье измерение. Счета гиперскейлеров могут быть непрозрачными: затраты на передачу данных между сервисами, хранение, выставляемое отдельно от вычислений, плата за исходящий трафик, которая растет по мере увеличения объемов событий. Ценообразование OVHcloud включает IOPS, трафик и резервное копирование. Вы видите стоимость до того, как выделите ресурсы. Никаких сюрпризов, когда пропускная способность вашего Kafka увеличивается.
Создание на OVHcloud
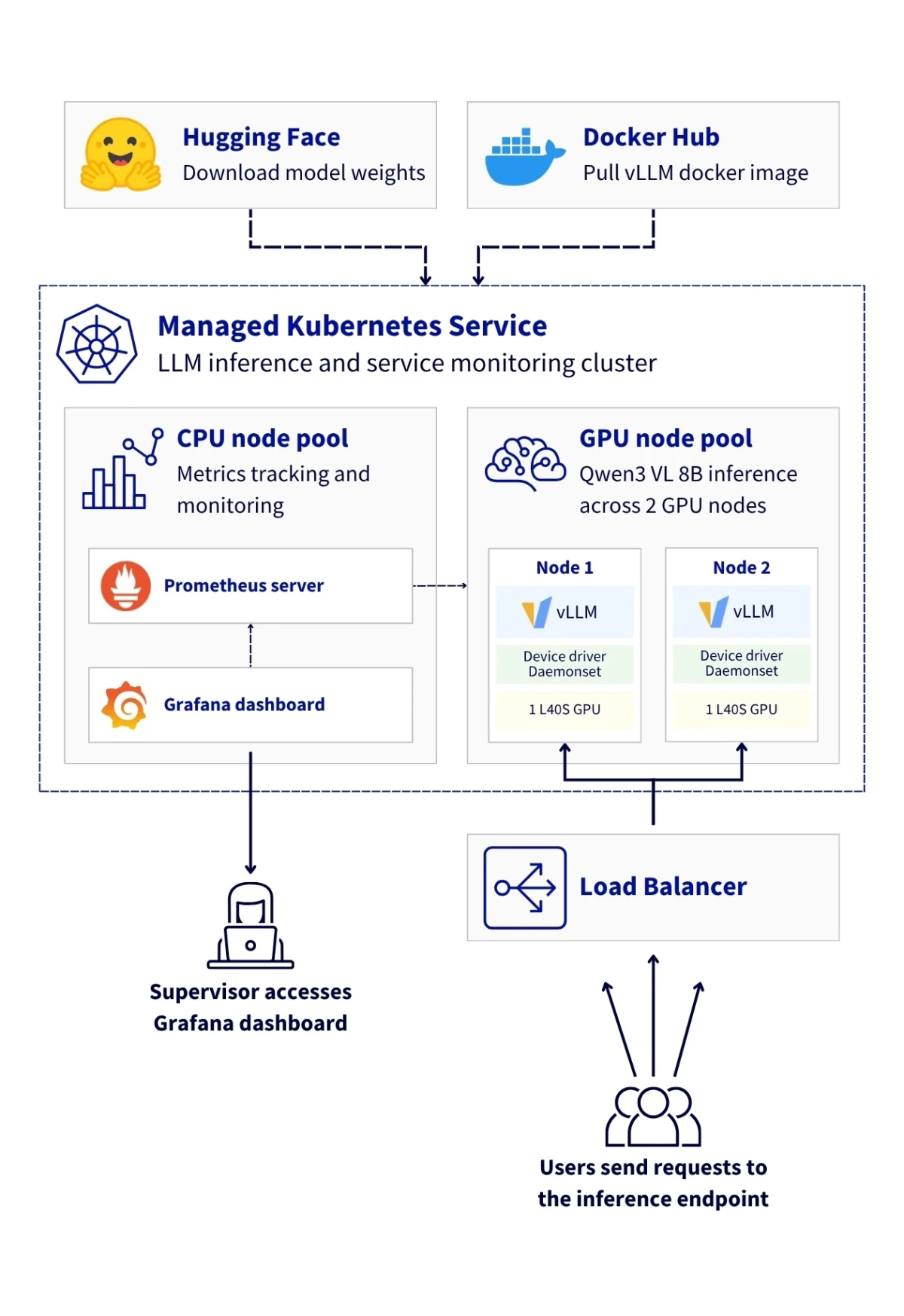
OVHcloud запускает все четыре уровня как управляемые сервисы, развертываемые и отслеживаемые из единой консоли.
Выделите Managed Kafka, выберите свой регион, и ваш кластер будет готов через несколько минут. Kafka 4.0 с KRaft означает, что не нужно настраивать или отслеживать ZooKeeper. Добавьте Managed Kafka Connect и настройте коннектор источника PostgreSQL с опциональным Debezium CDC для полного захвата изменений на уровне строк. Затем выделите Managed ClickHouse и добавьте коннектор-приемник, чтобы начать маршрутизацию событий из ваших топиков Kafka в таблицы ClickHouse, или выделите Managed OpenSearch и маршрутизируйте события туда. Добавьте Managed Grafana, чтобы подключиться к обоим движкам и начать создавать дашборды на живых данных.
Полный стек — это пять управляемых сервисов на одной платформе: PostgreSQL, Kafka, ClickHouse или OpenSearch (или оба) и Grafana. Одна консоль для выделения ресурсов и мониторинга. Один счет. Одна команда поддержки, которая понимает весь конвейер, а не только отдельные компоненты.
Начните с одного уровня
Вам не обязательно создавать весь конвейер в первый же день. Самая распространенная отправная точка — Kafka: настройте поток данных, прежде чем решать, куда он направляется. Как только события начинают перемещаться через топики Kafka, добавление ClickHouse или OpenSearch становится настройкой коннектора, а не перестройкой архитектуры.
Конвейер, который вы строите таким образом, модулен по своей конструкции. Каждый уровень добавляет независимую ценность. Команда, которая начинает с Kafka и добавляет ClickHouse шесть месяцев спустя, ничего не теряет в промежутке. Уровень Kafka уже выполнял свою работу. Конвейер вырос, не нарушая того, что уже работало.
Инфраструктура управляется. Данные остаются в ваших руках. Ценообразование прозрачно. Конвейер, который вам нужен, уже существует в одном стеке.

Комментарии
Категории
Случайное

Агентству на WordPress действительно

Безопасность на VPS: 10 шагов к защите
Настройка MX-записей для Gmail: полное
Продажа дизайнов Canva на Etsy: полное